Living on the Edge: Conflict Management and You
The PGDay Chicago 2025 Postgres conference has come and gone, and so too has my presentation on conflict management in Postgres Multi-Master clusters. For those who couldn’t attend this year, there’s no need to fret, as this blog will present all of the relevant details. By the end, you'll be well armed with the knowledge necessary to identify, mitigate, and avoid the worst scenarios which may arise in a distributed Postgres cluster.
Is Bi-Directional Logical Replication Implicitly Safe?
The release announcement for Postgres 16 included this cryptic note:
Finally, this release begins adding support for bidirectional logical replication, introducing functionality to replicate data between two tables from different publishers.
Despite how that may sound on the surface, that shouldn’t be interpreted as tacit permission or a resounding recommendation to immediately spin up an Active-Active logical replication cluster using native Postgres logical replication. Among other things, there are novel sequence rules, data merging concerns, conflict management, and the dreaded potential of node divergence.
None of these situations are managed by default, and a problem related to any one of these issues could result in implicit or explicit data loss. Consider a cluster distributed to three distinct geographic regions:
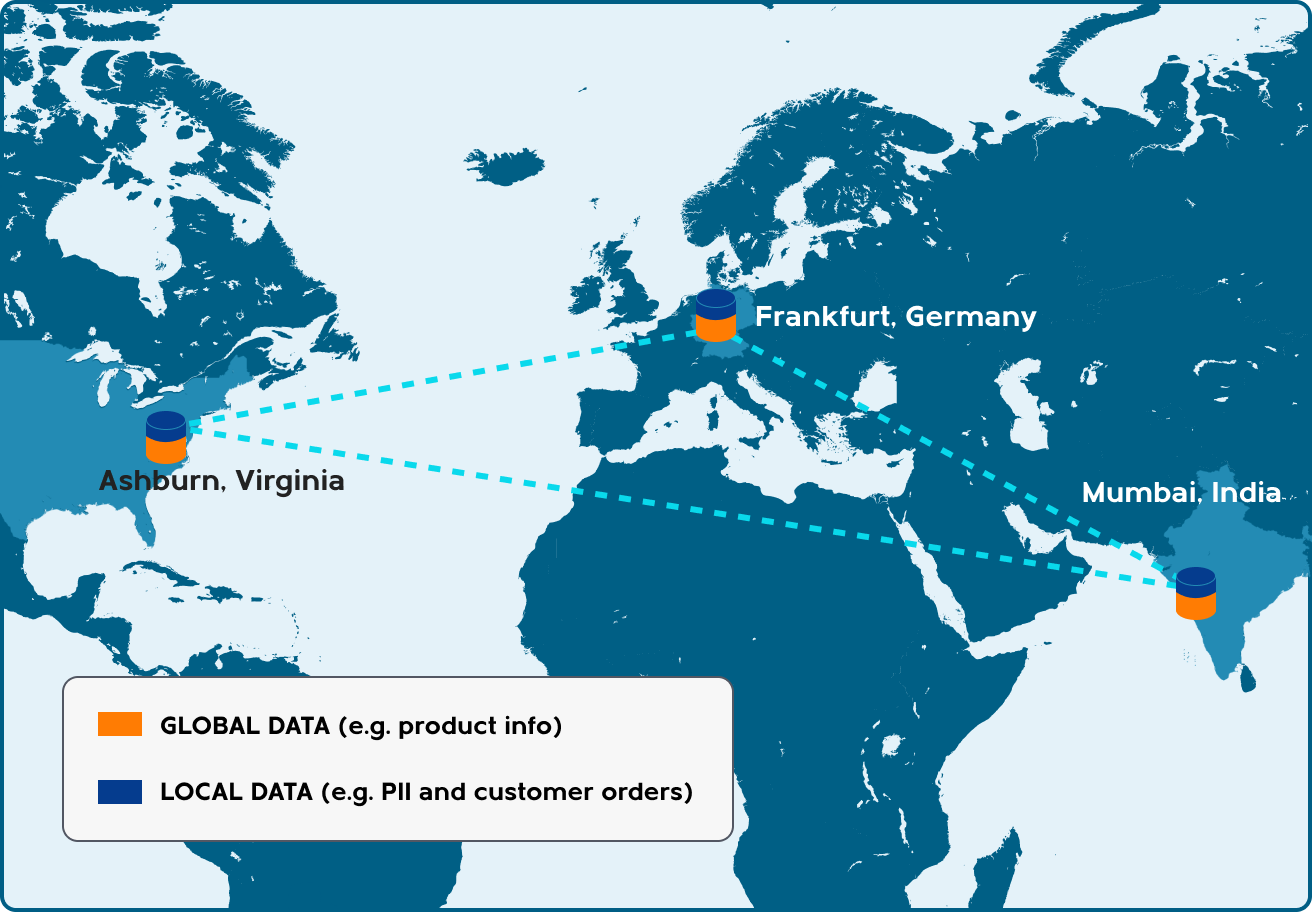 What might happen if Bob is in Ashburn, Virginia, and opens an account at ACME using his email address [email protected]? Probably nothing. Unless perhaps his wife is on vacation in Frankfurt, Germany and happens to be touring the ACME global office and decides to sign Bob up for an account because she knows he’s been meaning to do so. Through some providence of fate, this happens within the round-trip latency between Frankfurt and Ashburn, and now we have a problem. Which set of account credentials and related information do we retain?
What might happen if Bob is in Ashburn, Virginia, and opens an account at ACME using his email address [email protected]? Probably nothing. Unless perhaps his wife is on vacation in Frankfurt, Germany and happens to be touring the ACME global office and decides to sign Bob up for an account because she knows he’s been meaning to do so. Through some providence of fate, this happens within the round-trip latency between Frankfurt and Ashburn, and now we have a problem. Which set of account credentials and related information do we retain?
The answer to that question is why we’re here, and why solutions like pgEdge are necessary to successfully navigate the perilous seas of Multi-Master Postgres clusters. Let’s discuss the various types of complications we may encounter while operating a distributed Postgres cluster so we can do so safely.
In Theory
Those familiar with database cluster architectures may already be well acquainted with CAP theorem. Unlike ACID, which describes how databases like Postgres guarantee data validity, CAP is more focused on distributed operation within clusters. It goes like this:
Consistency - every read is recent, or an error.
Availability - every online node must respond to requests.
Partition Tolerance - disconnections shouldn’t disrupt operation.
Partitioned (distributed) clusters have either availability or consistency, never both. What happens if two nodes are disconnected? Either data may not be consistent between the two, or writes must be rejected or paused to avoid introducing inconsistencies.
But this isn’t quite right because it doesn’t account for network latency, which is a kind of built-in partition dictated by the speed of network traffic. The PACELC design principle aims to solve this conundrum. Rather than focusing purely on availability and consistency, it augments CAP by adding an extra logic branch:
Else even when a cluster is working normally without a partition
Choose between Latency or
Loss of Consistency
If you need a mnemonic for this, consider the humble Pack Elk:
 Most Multi-Master cluster solutions choose the latter (lost consistency) as the default. Essentially Postgres nodes in such a cluster accept local writes and transmit those changes to other participating nodes via logical replication. Until that transmission is complete and other nodes integrate that information, there is a small window where the cluster is not fully consistent. This is where problems begin for the unprepared.
Most Multi-Master cluster solutions choose the latter (lost consistency) as the default. Essentially Postgres nodes in such a cluster accept local writes and transmit those changes to other participating nodes via logical replication. Until that transmission is complete and other nodes integrate that information, there is a small window where the cluster is not fully consistent. This is where problems begin for the unprepared.
A single Postgres instance doesn’t suffer from this indignity. There’s a single source of truth much like a chess board, a single state of truth dictated by the board itself.
 In an Active-Active Postgres cluster, it’s more like a flock of starlings, where each node is generally going in the same direction most of the time. It’s a beautiful orchestration of form where no single node truly dictates the fate of the cluster.
In an Active-Active Postgres cluster, it’s more like a flock of starlings, where each node is generally going in the same direction most of the time. It’s a beautiful orchestration of form where no single node truly dictates the fate of the cluster.
 This is ultimately what we’re trying to achieve when deploying a distributed Postgres cluster.
This is ultimately what we’re trying to achieve when deploying a distributed Postgres cluster.
Disagreeable Outcomes
In a fully distributed Postgres cluster, the primary source of problems is the list of potential data conflicts, usually caused by giving preference to fast local writes rather than 100% consistency across the cluster. Such asynchronous operations lead to simultaneous changes which could be incompatible. The resulting conflicts make everyone sad, including the software components mediating the dispute.
When it comes to Postgres, there are basically four categories of conflict that may arise:
Naturally convergent conflicts
Resolvable conflicts
Divergent conflicts
(Bonus) Phantom conflicts
The first step to avoiding a situation is recognizing it - let’s tackle them one by one.
Convergent Conflicts
A convergent conflict is what happens when the order of operation doesn’t matter. It’s an idempotent result where, even if nodes apply changes with total disregard, they’ll all reach the same end state anyway. And remember, a “conflict” just means two different nodes performed some operation on the same row(s).
The first of these is an UPDATE / DELETE conflict:
Update happened first? It gets deleted
Delete happened first? Nothing to update
End state: the row is deleted
Next is a DELETE / DELETE conflict:
End state: the row is deleted
Then there’s the UPDATE / TRUNCATE conflict:
Update happened first? The table gets truncated
Truncate happened first? Nothing to update
End state: the table is truncated
Similarly, the DELETE / TRUNCATE conflict:
Delete happened first? The table gets truncated
Truncate happened first? Nothing to delete
End state: the table is truncated
And finally comes the TRUNCATE / TRUNCATE conflict:
End state: the table is truncated
All in all, these conflicts aren’t very interesting; they’re all dependent on either a single row being deleted, or the whole table being emptied. It doesn’t take much consideration to realize what will happen in the end.
Resolvable Conflicts
Then there are conflicts that can be resolved automatically by some default operation such as “Last-Write-Wins”, which assumes the most recent write should “win” the exchange on all nodes. This allows all nodes to remain consistent, but may result in data loss. Whether that overwritten row matters or not tends to depend on the application.
Let’s start with INSERT / INSERT conflicts:
Node A: INSERT ... (id, col1) VALUES (2, 10)
Node B: INSERT ... (id, col1) VALUES (2, 100)
Last "update" wins (default resolution method)
Result: one INSERT is discarded / overwritten
The conflict on the “id” column must be resolved, meaning we must discard either the value of 10 or 100, depending on the timestamp of the committing transaction. Will the transaction selected for discard make a difference?
This also applies to tables which rely on multiple unique constraints, such as a primary key and a unique index on an email column. Consider this scenario:
Node A: INSERT ... (id, email) VALUES (1, '[email protected]')
Node B: INSERT ... (id, email) VALUES (2, '[email protected]')
Last "update" wins (default resolution method)
Results:
○ One INSERT is discarded / overwritten
○ Loss of a primary key
○ Potentially orphaned foreign keys
The row will be consistent across the cluster, but which row? Will it be the email address with an ID of 1, or 2? Did the same transaction also insert dependent rows in another table with a foreign key referencing this ID? Should this even be handled automatically, or should there be some kind of custom resolution method to account for such scenarios? If Jim and Jen both entered a forest at the same time and only Jen returned, what happened to Jim?
The other types of resolvable conflict are both UPDATE / UPDATE variants. Consider this first example:
Node A: UPDATE t SET col1=100 WHERE id=4
Node B: UPDATE t SET col1=500 WHERE id=4
Last "update" wins (default resolution method)
Result: contents of col1 are discarded / overwritten
We can only retain a single update, but which one? If you imagine this is a bank app setting your total balance, it suddenly becomes a lot more relevant. But this can also go wrong in a more subtle way:
Node A: UPDATE t SET col1=100 WHERE id=4
Node B: UPDATE t SET col2='stuff' WHERE id=4
Last "update" wins (default resolution method)
Result: contents of col1 or col2 are discarded / overwritten
This happens because logical replication doesn’t just transmit the specific modification, it sends the entire resulting tuple. This is necessary because there could be triggers or other after-effects which further mutate the change being applied, so the only way to ensure an accurate representation is to capture the entire row contents at the end of the process.
Let’s examine the entire process:
Old tuple on both nodes: {id: 4, col1: 50, col2: 'wow'}
Node A: UPDATE t SET col1=100 WHERE id=4
Logical replication sees: {id: 4, col1: 100, col2: 'wow'}
Node B: UPDATE t SET col2='stuff' WHERE id=4
Logical replication sees: {id: 4, col1: 50, col2: 'stuff'}
The receiving node must pick one or the other, not both; there’s no automatic “merge” possible here. Using a Last Write Wins strategy would ensure a consistent picture across the cluster, but what about the column values we lost? Again, two people entered the forest and one vanished without a trace.
What happened to Jim?
Divergent Conflicts
Then there are conflicts that actually cause data to diverge on one or more nodes in the cluster on a permanent basis. Luckily this is usually caused by some kind of race condition between at least three nodes, so they’re much less likely to occur in the wild. Still, it’s important to know how they might occur so we can avoid triggering the surrounding circumstances.
Let’s start with an INSERT / UPDATE conflict between three nodes:
Node A: INSERT -> Node B
Node B: UPDATE -> Node C
Node C: ignores UPDATE
Node A: INSERT -> Node C
In this case, Node B received the INSERT before Node C, and subsequently updated the value. If that UPDATE reaches Node C before the INSERT from Node A, we have a problem. If Node C discards that phantom update for a row it doesn’t have, and later processes the INSERT, that means Node A and B have the updated value, and Node C does not. This is a node divergence. Once the cluster reaches this state, the only way to fix it is through manual intervention using some kind of data comparison tool like the Active Consistency Engine (ACE) from pgEdge.
This can also happen in an INSERT / DELETE scenario in a 3-node cluster:
Node A: INSERT -> Node B
Node B: DELETE -> Node C
Node C: ignores DELETE
Node A: INSERT -> Node C
Now Node C has a row that is missing on both Node A and Node B.
This situation is actually slightly worse than an INSERT / UPDATE conflict. A custom conflict management routine could convert the UPDATE to an INSERT using its original timestamp on nodes where the value is missing. Then when the original INSERT arrived, it would be skipped as being an older transaction. In the case of a DELETE, this isn’t possible because there is no way to modify a DELETE so it only affects the incoming INSERT.
Then there’s a INSERT / TRUNCATE conflict in a 3-node cluster:
Node A: INSERT -> Node B
Node B: TRUNCATE -> Node C
Node C: applies TRUNCATE
Node A: INSERT -> Node C
This time both Node A and Node B have no rows in the affected table, and Node C has diverged by retaining one rogue INSERT. There’s no easy fix for this situation either, as Node C has no way to know there’s a pending INSERT when the TRUNCATE arrives. Network latency makes fools of us all.
Phantom Conflicts
The last type of conflict is technically not a conflict at all, but an application may treat it like one. It won’t show up in logs, it’s not due to latency, and it can actually happen on a single Postgres node outside of replication of any kind. So what is it?
Consider this scenario:
App: INSERT; COMMIT -> Node A
Node A: COMMIT -> WAL -> Node B
Node A: Confirm !-> App
Node A: Crash
Node B: Becomes new write target
App: Connection aborted? Retry insert!
App: INSERT -> Node B
Postgres normally sends a confirmation message to the client after every transaction commit. But what happens if the node crashes during the confirmation and the client never receives the message? A good application would notice the error and try again. But thanks to that second attempt, a duplicate record now exists in the database.
How is that possible? Postgres always writes transactions to the WAL before applying them to backend data files. These WAL files are also used for crash recovery. The client never received an acknowledgement that the transaction committed successfully, but it succeeded nonetheless. Since the transaction is in the WAL, it will be retained following crash recovery of Node A and any replicas in the cluster. Yet the application layer thinks it failed and will probably try again.
The easiest way to avoid this is to rely on natural keys, or in the absence of those, a surrogate key that the application itself controls. Consider calling nextval() directly and supplying sequence values manually, or even relying on an external ID generator. Alternatively, the application retry loop should confirm whether the transaction failed with a SELECT prior to simply retrying.
Remember, this can affect even a non-distributed Postgres cluster. Trust, but verify.
Preventing the Inevitable
How do we mitigate or even avoid these scary conflict situations? Luckily there are a plethora of ways to address conflict potential in a distributed Postgres cluster. Let’s start with the easiest one of all!
Don’t Do That
An ounce of prevention is worth a pound of cure, after all.
Don’t do what? Consider the primary cause of conflicts: simultaneous operations occurring on the same data on different nodes. That happens because data may not have distinct structural or regional boundaries, or because a single application instance is interacting with multiple nodes simultaneously without regard for transmission latency.
Thus the simplest way to avoid conflicts is to control write targets
Use “sticky” sessions. Applications should only interact with a single write target at a time, and never “roam” within the cluster.
Assign app servers to specific (regional) nodes. Nodes in Mumbai shouldn’t write to databases in Chicago, and vice versa. It’s faster to write locally anyway.
nteract with specific (regional) data. Again, an account in Mumbai may physically exist in a globally distributed database, but multiple accessors increase the potential for conflicts.
Avoid unnecessary cross-node activity. Regional interaction also applies on a more local scale. If applications can silo or prefer certain data segments on specific database nodes, they should.
To solve the issue of updates on different database nodes modifying the same rows, there’s a solution for that too: use a ledger instead.
 This is probably a much more invasive application-level change than most, but some systems already do this and as a result, are automatically a great fit for distributed Postgres clusters.
This is probably a much more invasive application-level change than most, but some systems already do this and as a result, are automatically a great fit for distributed Postgres clusters.
Solving Conflicts with CRDTs
The official meaning of CRDT acronym is “Conflict-free Replicated Data Type”, but that’s cheating, so I usually refer to them as Conflict Resistant Data Types. These data types were specifically designed for distributed clusters or databases with constant asynchronous write conflicts. The latter occurs when two different writers modify a single row, but each started with an “old” copy of the row. Think of a SELECT -> UPDATE pattern.
As a result, CRDTs can actually be useful even in non-distributed Postgres clusters. In the context of a distributed Postgres cluster, there are basically two types of commonly available CRDT provided by the Active-Active extension:
Apply a diff between the incoming and existing values
Use a custom data type with per-node “hidden” fields
Additionally, these two approaches only work for numeric columns, like INT, BIGINT, FLOAT, NUMERIC, and so on. And of those two techniques, there are also two methods for providing them to Postgres: by patching how Postgres handles logical replication for numeric columns, or providing dedicated data types.
To understand how this works, let’s use a CRDT in the pgEdge Spock extension (a component of pgEdge Distributed Postgres):
CREATE TABLE account (
id BIGINT PRIMARY KEY,
total BIGINT NOT NULL DEFAULT 0
);
ALTER TABLE account
ALTER COLUMN total
SET (LOG_OLD_VALUE=true,
DELTA_APPLY_FUNCTION=spock.delta_apply);In this case, we’ve told Postgres that we need to track the previous value of the column, and that there’s a special callback function it should use when modifying values in that column. That function will ensure updates from any node in the cluster will add the difference between the value on the two nodes rather than the absolute value, resulting in a numeric merge operation.
If we used the EnterpriseDB BDR extension (a component of EDB Postgres Distributed) instead, it would look something like this:
CREATE TABLE account (
id BIGINT PRIMARY KEY,
total bdr.crdt_delta_counter NOT NULL DEFAULT 0
);This use case may appear simpler, but the BDR extension actually provides multiple CRDTs, each with its own unique rules, behaviors, and best practices. This also causes a certain amount of vendor lock-in, as it becomes impossible to uninstall the BDR extension so long as these column types are in use.
In either case, a delta-based CRDT works like this:
Both nodes start with a tuple: {id: 5, total: 100}
Either node: UPDATE account SET total = total + 100 WHERE id = 5
New resulting tuple: {id: 5, total: 200}
Old and new values are sent to the remote node
The delta function or type calculates:
○ total = local.total + remote.new.total - remote.old.total
○ total = 100 + 200 - 100 = 200
Here’s a scenario where that procedure specifically avoids a data conflict and also preserves the intended value across the cluster:
Initial tuple on both nodes: {id: 5, total: 100}
Node A adds 100, sends: {id: 5, total: 200}
Node B adds 400, sends: {id: 5, total: 500}
Node A: total = 200 + (500 - 100) = 600
Node B: total = 500 + (200 - 100) = 600
And indeed, an initial balance of $100, increased by $100 and then $400 would be a total of $600. This is exactly what we want, and the overhead from managing the deltas is generally minimal.
There’s also an alternative technique of maintaining separate hidden fields within the column for each node in the cluster. The benefit here is that each node only interacts with its own assigned sub-record, and the data type handles merging on display or retrieval of the stored value. There’s never a risk of conflict or unexpected merge behavior because nodes are always interacting with separate values.
Here’s how that works:
Initial tuple on both nodes: {id: 5, total: (100, 0)}
Total displayed as 100
Node A adds 100
Node B subtracts 50
New tuple: {id: 5, total: (200, -50)}
Total displayed as 150
If a third node is added to the cluster later, the CRDT will simply add another hidden field to the column when rows are updated by the new node. However, there's an important limitation to this technique: values can never be set to zero without using a special function. Consider this scenario:
Initial tuple on both nodes: {id: 5, total: (200, -50)}
Total displayed as 150
Node A sets total to 0
Node B does nothing
New tuple: {id: 5, total: (0, -50)}
Total displayed as -50
Since each node only interacts with its own dedicated sub-field, it’s impossible to reset the column value to zero without having every node also reset its data. The only real way to set such CRDT columns to zero is to use a special utility function that will essentially revert the column to an initial empty state. Once that action enters the logical replication stream, every other node will also empty that column. Applications which intend to use these types of CRDT would definitely need to account for this behavior.
Key Management
Surrogate keys are probably the most commonly leveraged technique for assigning unique values to primary keys in Postgres tables. However, this approach often assumes a single source of key values, or fails to account for the presence of other nodes. If two nodes rely on a sequence for assigning values, this sequence will frequently yield the same value on both nodes, causing constant conflicts and resulting in data loss during INSERT statements.
There are effectively four methods for safely generating surrogate keys which are guaranteed to be unique across every node in distributed Postgres clusters:
Sequence offsets
Globally unique keys
Global allocations
External key generator
We’ll explore the first three options here, since it’s incredibly uncommon to leverage an external service to generate IDs rather than doing it locally or algorithmically.
Sequence Offsets
Sequence offsets are the most backward compatible approach because they rely on no outside technology or extension. They work like this:
For every sequence on Node 1:
ALTER SEQUENCE foo_id_seq
RESTART WITH 1001
INCREMENT BY 10;For every sequence on Node 2:
ALTER SEQUENCE foo_id_seq
RESTART WITH 1002
INCREMENT BY 10;Afterwards, the sequence on Node 1 will generate values such as 1001, 1011, 1021, and so on, while Node 2 will not conflict, as its values will be 1002, 1012, 1022, etc.. The primary difficulty here is never forgetting to apply these modifications to all sequences on a node when it joins the cluster. New sequences will also require this treatment on every node. Further, the width of the increment must account for the maximum number of expected cluster nodes, and can never really be expanded afterwards. The ongoing amount of maintenance here is incredibly high.
Globally Unique Keys
It’s also possible to algorithmically generate surrogate keys in such a way that they’re guaranteed to be unique across the cluster. The most common approach already in use in many applications is through leveraging UUIDs. Postgres has a built-in function for this:
SELECT gen_random_uuid();
gen_random_uuid
--------------------------------------
be755079-f39b-46dc-98ad-8eeab349880dBetter yet, Postgres 18 is expected to have native support for UUID v7, which should improve compatibility with BTREE indexes.
Another approach is to use a Snowflake ID, an algorithmic technique that combines a timestamp, node identifier, and a millisecond-scale sequence, popularized by sites like Twitter and Instagram. The pgEdge Distributed Postgres stack includes the Snowflake extension, which provides alternative nextval() and currval() functions for generating these kinds of values.
SELECT * FROM snowflake.nextval('orders_id_seq'::regclass);
nextval
--------------------
136169504773242881The primary drawback when using these values is that they’re always 64-bit integers. This is fully compatible with the Postgres BIGINT type, but applications may require explicit modification to support such large 64-bit values, such as JavaScript and its BigInt type.
Global Allocations
The last technique we’ll discuss is the use of globally allocated sequence ranges. In this approach, each node requests a contiguous block of values from the other nodes in the cluster, and they all agree on block assignments. As a result, Node 1 may have two 1-million row chunks from 1-2,000,000, Node 2 uses 2,000,001 to 4,000,000, and Node 3 has 4,000,001 to 6,000,000.
Nodes retain two blocks so they can request another block once they start consuming the second. INTs may default to smaller chunks such as 1-million, while BIGINTs can reasonably assign larger 1-billion row chunks.
This process is something a distributed cluster extension can do by hooking into internal Postgres extension hooks. But it also means there’s a maintenance process and a consensus aspect for distributing and using assigned blocks. On the other hand, unlike Snowflake IDs, there’s no potential for number length incompatibility, and unlike sequence offsets, there’s no need to manually modify each sequence on every node.
Sequence Safety
While we’re on the topic of sequences, we need to look at how Postgres uses them internally. We’ve all been told not to do this:
CREATE TABLE serial_example (
id BIGSERIAL PRIMARY KEY
);Why? Because there’s a lot of hidden behind the scenes magic that doesn’t mesh well with current SQL standards. This is actually what happens when using SERIAL or BIGSERIAL in Postgres:
CREATE TABLE serial_example (
id BIGINT PRIMARY KEY
);
CREATE SEQUENCE serial_example_id_seq;
ALTER SEQUENCE serial_example_id_seq
OWNED BY serial_example.id;
ALTER TABLE ONLY public.serial_example
ALTER COLUMN id
SET DEFAULT nextval('public.serial_example_id_seq');Postgres creates an implicit sequence and associates it with the table. Usage grants to the table do not cascade to the sequence, and the value is supplied by a weak “default” clause. As a result, many new applications and schemas use IDENTITY syntax instead:
CREATE TABLE ident_example (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY
);Now there’s no more magical nextval shenanigans, the word ALWAYS means what it says, and it’s standard SQL. There’s even extra syntax to set the starting point, increment size, and other attributes. It’s great, right? Well maybe
What happens in Active-Active clusters? We can no longer explicitly substitute our own nextval function, so we may be stuck with the monotonically advancing sequential values provided by the identity. It means we can’t use an alternative ID generator such as snowflake, timeshard, galloc, or anything else unless the distributed cluster extension can override the appropriate identity calls. The application definitely can’t do it with something as simple as the Snowflake extension.
Ironically the new and recommended approach which is perfect for a replicated Postgres cluster is actually too inflexible for a distributed cluster. It may even be necessary for application schemas using IDENITITY to reverse migrate to SERIAL, BIGSERIAL, or using DEFAULT explicitly.
Fixing Divergent INSERT / UPDATE Conflicts
When we discussed the topic of INSERT / UPDATE conflicts, we noted that Node C would ignore an UPDATE if it arrived prior to the dependent INSERT. One way to fix that would be for the distributed Postgres extension to convert the UPDATE to an INSERT. Then when the original INSERT arrives, its earlier timestamp means it loses the Last Write Wins battle, and the risk of divergence vanishes.
The only caveat here is that updates don’t normally include TOAST data unless the toasted value itself is modified. This means the distributed Postgres extension must account for this and manually detoast the column value while performing the logical decoding step. If the extension doesn’t perform this translation, the only other option is to declare the entire row as a replica identity like this:
ALTER TABLE foo REPLICA IDENTITY FULL;This forces Postgres to retrieve the toasted value and add it to the logical replication stream automatically. This may affect logical replication efficiency if there are a lot of large text fields, but it facilitates the UPDATE to INSERT conversion necessary to avoid this type of conflict.
Historical Relevance
Finally, there’s a technique for addressing divergent conflicts involving DELETE statements which no current distributed Postgres solution provides. Postgres Multi Version Concurrency Control works by retaining old row records in the table heap. We ran into a divergent conflict earlier in this article because a node has no way to reject an INSERT for a previously DELETEd row. But what if we did?
Consider how the hot_standby_feedback configuration parameter works. It allows a physical standby node to inform the primary of the lowest visible XID for any active transactions. The primary will then refrain from performing destructive maintenance on these visible tuples. A distributed Postgres cluster should know the timestamp from the oldest transaction from any other node in the cluster. What if it used that value to prevent similar cleanup across the cluster?
This “tombstone” record would follow the same rules as Postgres transaction visibility normally would, but would allow the distributed Postgres extension to physically examine the older record if present. If a DELETE removes a record, but there are pending transactions which might need to see that delete, the tombstone would make that possible.
What if the DELETE arrived before any INSERT? Rather than discarding the event, the distributed Postgres extension could insert it purely as a tombstone record. Once all transactions older than the DELETE have replayed, the tombstone snapshot would move to the next outstanding XID the same way as hot_standby_feedback.
Barring this kind of advanced automatic handling, the easiest way to avoid divergent conflicts caused by DELETE or TRUNCATE is to avoid executing either. It’s actually fairly common for databases to never delete data, electing instead to use a technique called a “soft” delete. A soft delete is simply something like this:
UPDATE my_table
SET delete_ts = now()
WHERE id = 150;In the event of a system audit, the record is still there, its old contents are still available, and there’s no risk of a divergent conflict because the existing record also acts as a tombstone. Some DBAs and data scientists actually strongly recommend always doing this even in non-distributed Postgres clusters. Having a reliable audit-trail is sometimes more important than having a pristine database with no “unnecessary” records.
Final Words
Managing a distributed Postgres cluster is hardly a trivial commitment. But it’s certainly less daunting when armed with the right product such as pgEdge Distributed PostgreSQL, knowledge of the possible conflicts and related edge cases, and a clear understanding of the best mitigation techniques. Any application stack can excel in a distributed cluster environment by following certain precautions.
As always, the power of Postgres makes it possible!

