The Joy of Deploying pgEdge Distributed PostgreSQL Using Ansible
Once upon a time, the Perl programming language earned the nickname “the Swiss Army chainsaw of scripting languages” from its users. In many ways, Ansible has attained a similarly lofty reputation for orchestrating infrastructure. Many experienced Postgres DBAs figured this out a long time ago, jealously hoarding collections, roles, and playbooks and yearning for a day when they too could sit back and watch their new cluster “compile”.
We at pgEdge understand this compulsion all too well, extensively leveraging Ansible for internal testing purposes. It’s hard to beat the convenience of whipping up a few VMs and building a full active-active pgEdge distributed Postgres cluster within a few minutes, bombarding it with millions of transactions to reveal operational edge cases, and then lather, rinse, and repeat. Some time during this unsanctioned VM abuse, we realized everyone else might want to join in on the fun, and so pgedge-ansible was born.
What is pgedge-ansible
Frankly, pgedge-ansible does exactly what it says on the tin: it’s an Ansible collection built specifically to deploy pgEdge clusters. It provides configurable roles for spinning up a variety of pgEdge architecture stacks, from a simple two-node cluster, all the way to our 10-node Ultra HA design featuring six Postgres nodes, independent Patroni failover management, HAProxy traffic control, and pgBackRest backup management.
While the pgEdge CLI platform tool has been around for a while and fulfills a similar role when combined with a JSON cluster definition file, there are certain advantages to including Ansible. Principal among them is the ability to provide more direct control over the full hardware and software stack. Ansible is designed to be flexible, either by using roles in playbooks exactly as intended, or by integrating various customizations the collection authors may not have anticipated.
In true Ansible fashion, the pgedge-ansible role provides a minimum reference implementation and most parts may be readily swapped out to better match existing infrastructure. Don’t need HAProxy and have a role for configuring a common F5 load balancer or an AWS elastic load balancer (ELB)? Be our guest! Want to use Barman instead of pgBackrest for backup management? Please feel free. We want to make using pgEdge easy and convenient, and that means meeting the customer where they are.
How does it work?
We hope you’ll love this part, because it’s incredibly easy to use. We’ve included playbooks for two sample architecture designs in the collection:
A simple cluster consisting only of pgEdge distributed Postgres nodes.
A “batteries included” cluster with all the trimmings we like to call “Ultra HA”.
The collection operates by assuming every pgEdge node resides in its own “zone”. Something like this:
 This design makes it possible to extend the zone designation to far more sophisticated clusters like this:
This design makes it possible to extend the zone designation to far more sophisticated clusters like this:
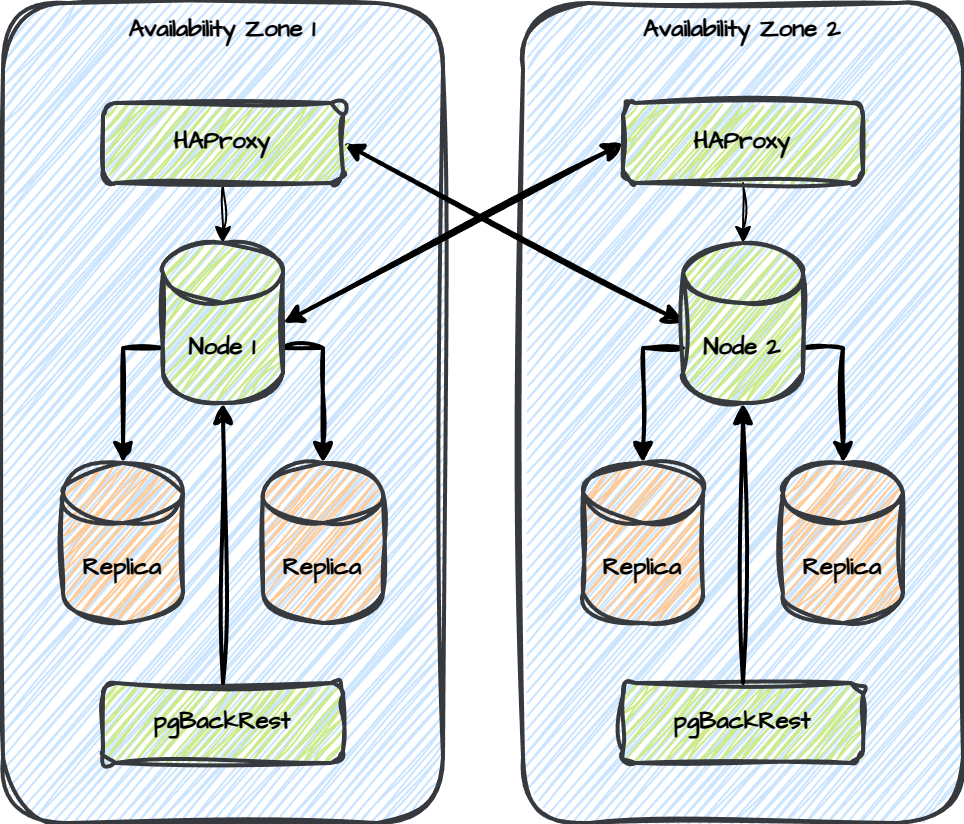 The simple cluster relies on only four roles:
The simple cluster relies on only four roles:
init_server - Get the server ready to run a pgEdge cluster.
install_pgedge - Install the pgedge CLI platform software.
setup_postgres - Create a Postgres instance capable of running pgEdge.
setup_pgedge - Initialize each pgEdge node and wire the zones together for Active-Active logical replication.
The Ultra HA cluster requires a substantially longer list since we also have to orchestrate Patroni, etcd, HAProxy, and pgBackRest as well:
init_server - Get the server ready to run a pgEdge cluster.
install_pgedge - Install the pgedge CLI platform software.
setup_postgres - Create a Postgres instance capable of running pgEdge.
install_etcd - Retrieve and install etcd to act as a DCS for Patroni.
install_patroni - Retrieve and install Patroni to manage replicas and failover per zone.
install_backrest - Retrieve and install pgBackRest for backup management.
setup_etcd - Configure etcd to create a quorum within the node zone.
setup_patroni - Configure Patroni for its local etcd and pgEdge Postgres instance. This will also bootstrap the replicas.
setup_haproxy - Retrieve, install, and configure HAProxy based on the Patroni-managed nodes in the zone.
setup_pgedge - Initialize each pgEdge node and wire the zones together for Active-Active logical replication. This has to come after setup_haproxy because each zone needs to communicate through the proxy to make sure it always reaches the current pgEdge primary node in that zone.
setup_backrest - Configure pgBackRest to back up nodes in its zone, and take an initial backup to bootstrap everything. It will only back up the current Primary node.
That’s a lot of work to do to set up a cluster! But the beauty of Ansible is that it handles all of that. The roles even recognize three group names to keep inventory files simple:
pgedge - Nodes where pgedge is being installed or managed. These are automatically sub-grouped by zone.
haproxy - Nodes where HAProxy is running. These are also sub-grouped automatically by zone because each HAProxy will only perform node health checks for routing within that zone.
backup - Dedicated backup servers. These are also sub-grouped automatically by zone so each zone has its own set of backups.
Installation and use
Using the pgedge-ansible collection is pretty straightforward; we’re doing our best to keep everything compatible with Ansible best practices and intend to eventually submit everything to Ansible Galaxy.
Installation is about what you’d expect:
git clone [email protected]:pgEdge/pgedge-ansible.git
cd pgedge-ansible
make installOnce the collection is installed, using it only requires activating the collection and using the roles. Consider this inventory file:
pgedge:
hosts:
192.168.6.10:
zone: 1
192.168.6.11:
zone: 2That’s two nodes, each with its own logical availability zone. Then we just need a playbook to deploy the cluster:
- hosts: pgedge
collections:
- pgedge.platform
roles:
- init_server
- install_pgedge
- setup_postgres
- setup_pgedgeAnd then we just need to run the playbook:
ansible-playbook -i inventory.yaml deploy-cluster.yamlAssuming everything went as expected, we should end up with an active-active pgEdge distributed Postgres cluster with DDL replication enabled by default. But don’t take our word for it, try it yourself!
The work of a DBA is never truly done, and we hope this makes your life just a bit easier. Fully active-active Postgres clusters are hardly trivial to deploy and administer, but a good Ansible collection can certainly improve the situation considerably. There’s an exciting new world of running writable Postgres nodes “on the edge”, and now diving in is easier than ever before.
Now’s your chance to experiment. Let us know if pgedge-ansible helped you bring your Postgres cluster to the next level.

