From Managed PostgreSQL to Production RAG: Build Your Own Ellie in pgEdge Cloud
If you've used docs.pgedge.com recently, you've probably met Ellie. Ask her how to set up multi-master replication, or what port the MCP Server listens on, and she pulls the relevant documentation, assembles it into context, and gives you a grounded answer with source citations. She doesn't guess or hallucinate. She finds the actual docs and synthesizes an answer from them.
Ellie is a RAG Server deployment. The pgEdge RAG Server is an API server for retrieval-augmented generation that runs hybrid search (vector similarity plus BM25) over content stored in Postgres, then sends matches to an LLM for grounded answers.
The pgEdge RAG Server can now be deployed in pgEdge Cloud as a managed service. Deploy it alongside your database, point it at your tables, and your application gets the same pipeline Ellie uses, running against your data.
Prefer to run it yourself? The RAG Server is 100% open source under the PostgreSQL License and available on GitHub. It's a single Go binary you point at any PostgreSQL 14+ database with pgvector installed, configured via YAML, with your own API keys for OpenAI, Anthropic, Voyage, or local Ollama. Hybrid search (vector similarity plus BM25), token budgets, and streaming responses are all in the binary. The Agentic AI Toolkit FAQ has more on how it fits with the rest of the toolkit, including Vectorizer and Docloader.
What kinds of problems do you run into building RAG pipelines from scratch?
If you've tried building a retrieval-augmented generation pipeline from scratch, you already know this: the problems compound on each other. You start with vector similarity search to find semantically relevant documents, but pure vector search misses exact-term queries. Someone asks about "error code 4012" or "order ABC-1234" and the semantic search returns conceptually related results instead of the one document that actually mentions that string. So you add BM25 keyword matching. Now you have two ranked result sets and you need a fusion algorithm to combine them without letting either method dominate the other.
That's just retrieval. You also need token budget management so a single query doesn't fire your entire document corpus at the LLM and blow through your API credits. You need streaming infrastructure so your UI can render answers progressively instead of making users stare at a spinner for eight seconds. You need health checks, connection pooling, error handling, and production monitoring. Each of these is individually tractable, but together they represent a ton of engineering before you've written a single line of the feature your users actually wanted.
We built all of that into the RAG Server. Ellie was the first deployment. Now it's available as a managed service so you can build your own.
How does a RAG pipeline work?
When your application sends a question to the RAG Server API, the pipeline runs in sequence. The embedding provider converts the question into a vector. That vector gets compared against pre-computed embeddings stored in your Postgres tables using pgvector, pulling back the document chunks that are semantically closest to what was asked. At the same time, BM25 keyword search runs against the same tables, catching the exact-term matches that vector search tends to miss.
Both result sets feed into Reciprocal Rank Fusion (RRF), which merges them into a single ranked list. RRF is simple and effective: it scores each document based on its rank position in both lists, so a document that appears near the top of both searches rises to the top of the combined results without needing to normalize scores across methods. The top results get trimmed to fit within your configured token budget (so costs stay predictable), bundled with the original question, and sent to the completion LLM. The response comes back as a grounded answer, optionally with source citations and relevance scores so your application can show users exactly where the information came from. The whole pipeline runs in a single container, exposes a RESTful API, and supports streaming via Server-Sent Events for real-time answer generation in your UI.
How do I deploy a RAG server alongside hosted PostgreSQL-as-a-service?
RAG Server deploys alongside your database as a managed service in pgEdge Cloud. Navigate to your database in the Cloud console, open Services, and deploy a RAG Server. The configuration covers three areas.
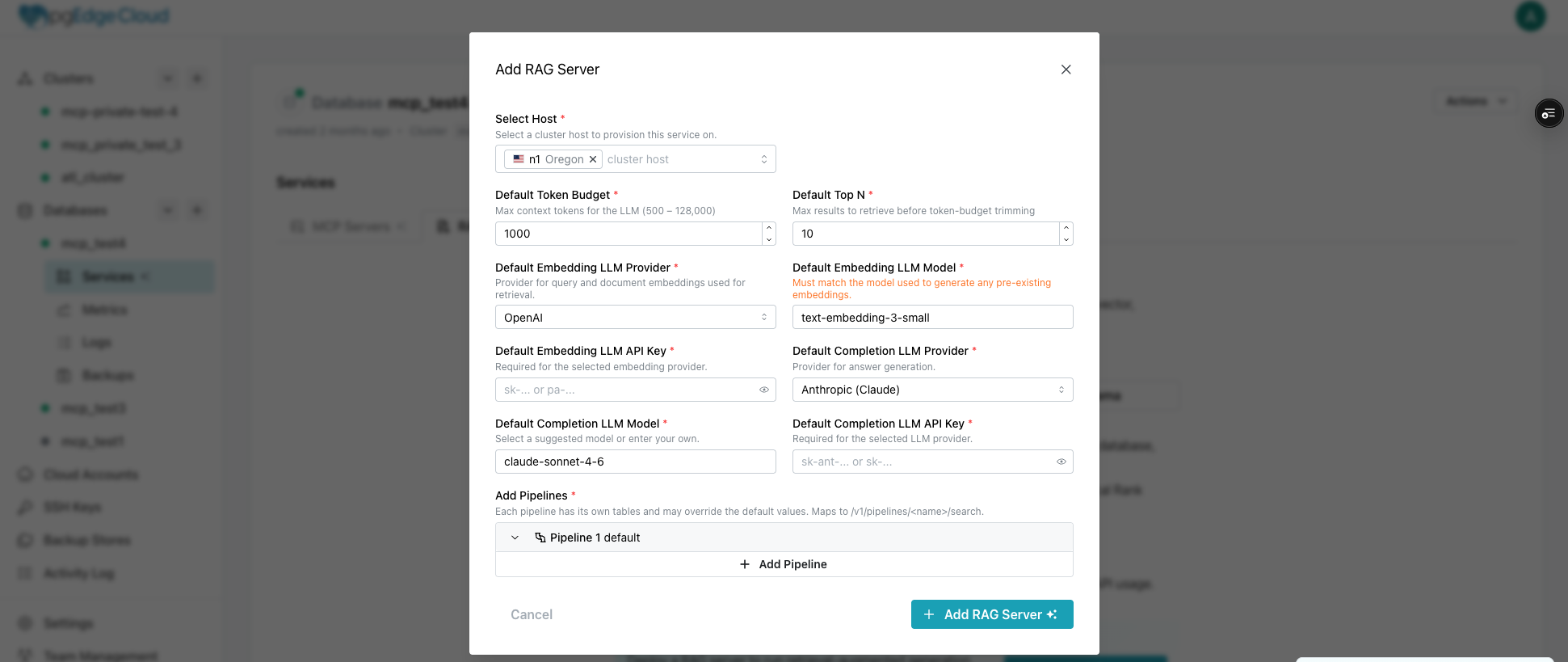 Providers. Choose your embedding provider (OpenAI or Voyage) and your completion provider (Anthropic or OpenAI). You can mix them: Voyage for embeddings and Anthropic for completions works fine, and that's exactly what a lot of teams need. Each provider gets its own API key, encrypted and stored by the platform. One important constraint: if you're using the pgEdge Vectorizer to generate your document embeddings, the embedding provider and model you configure here must match what the Vectorizer uses. The RAG Server embeds your query at search time, and the Vectorizer embeds your documents at ingestion time. If those models don't match, the vectors live in incompatible semantic spaces and similarity search returns nonsense.
Providers. Choose your embedding provider (OpenAI or Voyage) and your completion provider (Anthropic or OpenAI). You can mix them: Voyage for embeddings and Anthropic for completions works fine, and that's exactly what a lot of teams need. Each provider gets its own API key, encrypted and stored by the platform. One important constraint: if you're using the pgEdge Vectorizer to generate your document embeddings, the embedding provider and model you configure here must match what the Vectorizer uses. The RAG Server embeds your query at search time, and the Vectorizer embeds your documents at ingestion time. If those models don't match, the vectors live in incompatible semantic spaces and similarity search returns nonsense.
Document tables. Point the RAG Server at the tables holding your embedded documents. For each table, you specify the text column (the actual content) and the vector column (the pgvector embeddings). A single pipeline can search across multiple tables in the same database, so your support docs, knowledge base articles, and product documentation can all feed a single retrieval endpoint.
Search settings. Toggle hybrid search on or off, adjust the vector weight to balance semantic and keyword relevance, and set a token budget to cap how much context gets sent to the LLM per query.
Once deployed, the platform generates a bearer token for your application. The API call looks like this:
curl -X POST \
https://rag-{service_id}.your-cluster.pgedge.cloud/v1/pipelines/default \
-H "Authorization: Bearer YOUR_TOKEN" \
-H "Content-Type: application/json" \
-d '{"query": "How do I configure multi-master replication?"}'Add "stream": true to get Server-Sent Events instead of a single JSON response. The platform handles TLS termination, token validation at the ingress layer, and health monitoring. Ten minutes from configuration to a working API endpoint, if you already have embedded documents in your tables.
What are real-world examples of using RAG pipelines in production?
A support team with documentation already chunked and embedded in Postgres can deploy a bot that gives customers grounded answers instead of a list of keyword-matched FAQ pages. The response cites the specific doc sections it drew from, so users can verify the answer and dig deeper if they need to.
A compliance team at a financial services firm can build internal Q&A tooling where every response traces back to the specific regulation or policy section that informed it. In regulated industries, that audit trail is not optional. RAG Server returns source documents with relevance scores, and your application decides how to surface that provenance to users.
A product team can replace basic keyword search on their documentation site with something that actually understands what users are asking. "How do I set up replication" and "configure multi-master across regions" should return the same docs. With hybrid search combining semantic understanding and keyword matching, they do.
These are all variations of the same pattern: take knowledge that's already in your database, and make it accessible through natural language. The RAG Server handles the retrieval, the ranking, the token management, and the LLM orchestration. Your application just calls an API.
Ready to get started?
RAG Server is available now to all pgEdge Cloud customers at no additional charge. You bring your own LLM and embedding API keys, and you pay those provider costs directly. The deployment, the container, the ingress, the auth, the monitoring: all included.
Your database needs pgvector enabled and documents with pre-computed vector embeddings. If you're starting from raw documents (HTML, Markdown, reStructuredText), the pgEdge Docloader handles loading them into Postgres with format conversion and metadata extraction. From there, the pgEdge Vectorizer extension handles chunking and asynchronous embedding generation inside Postgres. For repeat queries, pg_semantic_cache stores results keyed by vector similarity, so questions phrased differently but meaning the same thing return from cache instead of re-running the full retrieval pipeline. Docloader gets your documents into the database, Vectorizer turns them into searchable embeddings, the RAG Server makes them answerable, and pg_semantic_cache keeps repeat answers cheap. The whole path from raw docs to a working Q&A API stays inside Postgres.
And you don't need to be a pgEdge Cloud customer to use any of this. Docloader, Vectorizer, pg_semantic_cache, and the RAG Server are all open source under the PostgreSQL License. Self-host them against any Postgres 14+ cluster you're already running and the pipeline behaves the same way; pgEdge Cloud just runs the operational layer for you. If you have any questions along the way, get in touch with us — we're only a message away on Discord.
Go to docs.pgedge.com and ask Ellie a question first. See what a finished RAG deployment feels like from the user's side. Then sign up for pgEdge Cloud or navigate to your database's Services tab and build your own. The documentation has the full configuration reference and API integration guide.

