How Patroni Brings High Availability to Postgres
Let’s face it, there are a multitude of High Availability tools for managing Postgres clusters. This landscape evolved over a period of decades to reach its current state, and there’s a lot of confusion in the community as a result. Whether it’s Reddit, the Postgres mailing lists, Slack, Discord, IRC, conference talks, or any number of venues, one of the most frequent questions I encounter is: How do I make Postgres HA?
My answer has been a steadfast “Just use Patroni,” since about 2017. Unless something miraculous happens in the Postgres ecosystem, that answer is very unlikely to change. But why? What makes Patroni the “final answer” when it comes to Postgres and high availability? It has a lot to do with how Patroni does its job, and that’s what we’ll be exploring in this article.
The elephant in the room
By itself, Postgres is not a cluster in the sense most people visualize. They may envision a sophisticated mass of interconnected servers, furiously blinking their lights at each other, aware of each computation the others make, ready to take over should one fail. In reality, the “official” use of the word “cluster” in the Postgres world is just one or more databases associated with a single Postgres instance. It’s right in the documentation for Creating a Database Cluster.
“A database cluster is a collection of databases that is managed by a single instance of a running database server.”
The concept of multiple such instances interacting is so alien to Postgres that it didn’t even exist until version 9.0 introduced Hot Standbys and streaming replication back in 2010. And how do hot standby instances work? The same way as the primary node: they apply WAL pages to the backend heap files. Those WAL pages may be supplied from archived WAL files or by streaming them from the primary itself, but it’s still just continuous crash recovery by another name.
This matters because each Postgres node still knows little to nothing about other nodes in this makeshift cluster over 15 years later. This isn’t necessarily a problem in itself, but it betrays a certain amount of willful ignorance on the part of each node. Why doesn’t each node care about, or even really acknowledge the other nodes exist at all?
Of course each node should care that the other nodes exist! And that’s how every Postgres HA tool was born. Slony and PgPool-II were probably the first of these, using Pacemaker and Corosync was always popular in the early days, then came Bucardo, repmgr, and EFM. Those are just the more noteworthy examples known by most of the community.
But a funny thing happened after Patroni’s initial release: the relentless torrent of Postgres HA tools suddenly ceased. Everyone immediately understood something made it fundamentally different from its predecessors. Let’s talk about why.
What Patroni does
Patroni does something Postgres still doesn’t do: it builds a cluster of Postgres nodes. It does this by facilitating what I like to call a “HAProxy and DCS Sandwich” that looks something like this:
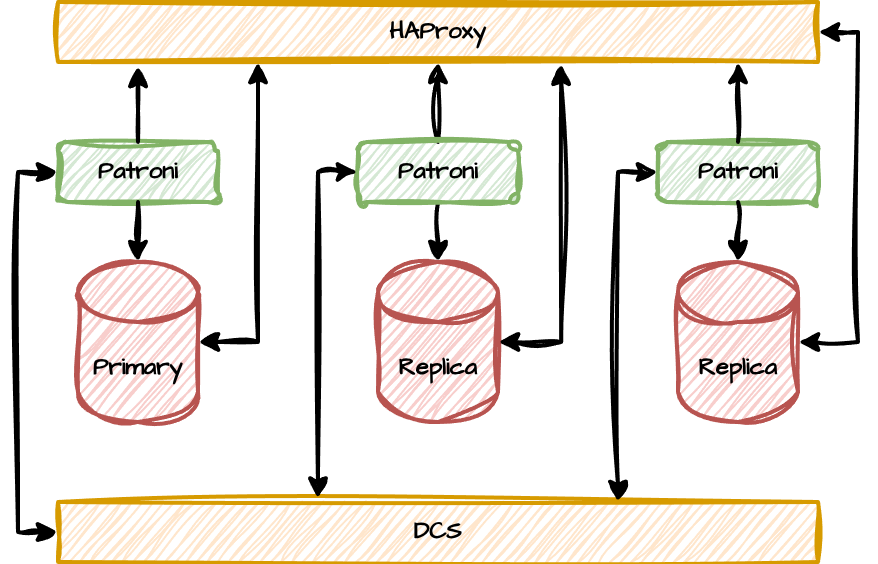 Think of it like a Postgres BLT where Patroni acts as the lettuce that brings everything together. It’s the missing communications nexus that records the composition of the cluster, the status of its members, and routes connections where they need to go.
Think of it like a Postgres BLT where Patroni acts as the lettuce that brings everything together. It’s the missing communications nexus that records the composition of the cluster, the status of its members, and routes connections where they need to go.
Let’s dive a bit deeper into how it does all of this, and why that matters to everyone from hobbyists to fortune 500 corporations.
Quorum
The first and most important aspect of Patroni’s operational role is that of maintaining quorum. Here’s a handy definition for a quorum:
The minimal number of officers and members of a committee or organization, usually a majority, who must be present for valid transactions of business.
The critical aspect here is the voting majority, otherwise known as a Consensus. The standard formula for this for some number of nodes N is: N/2 + 1. While a two-node cluster would need both nodes to remain online to maintain a majority, a three-node cluster would also require two nodes to maintain a majority. It’s this “extra” node that creates resilience in a network cluster. Should one node become isolated from the others, either through failure or a network partition, the quorum remains and the cluster stays operational. More nodes usually also confers better protection; three is best out of five, after all. Due to communication overhead caused by node topology, most consensus layers suggest staying below a “handful” of nodes, which tends to mean “fewer than ten”.
Ironically, Patroni handles quorum by delegating that responsibility to another piece of software entirely. Patroni reports compatibility with four different key/value or Distributed Configuration Store services, including etcd, Consul, ZooKeeper, and even Kubernetes. In reality, Patroni doesn’t really care where the DCS layer lives or what it’s composed of, just so long as it responds to read and write requests.
That’s why the “DCS” layer in the diagram is a flat plane supporting all of the Postgres nodes. The DCS could be anywhere, using any number of nodes, and Patroni doesn’t have to manage it.
Orchestration
Patroni is a specialized high-availability tool designed specifically for Postgres. As a result, it knows how to manage anything associated with a cluster of Postgres instances, including but not limited to:
starting and stopping the Postgres service.
promoting replicas.
bootstrapping new replicas.
demoting primary nodes.
Log Sequence Numbers (LSNs).
replication slots.
Patroni stores all metadata in the DCS layer, updating it regularly for every node. The “cluster” always knows the status of all nodes, including any replication lag. The magic of how Patroni works so well is how it knows which node is the Primary for the cluster: the leadership token. Here’s how it works:
Patroni checks to see if the current node owns the leadership token.
If yes, refresh the token and restart the loop.
If no, can this node take the leadership token?
If yes, take the token, promote this node, and restart the loop.
If no, act as a normal replica, reconfigure for the current primary if needed.
There are other steps involved of course, but since the consensus layer is distributed, there can only ever be one leadership token. Once a node has the token, no other node can claim to be the primary node. Based on which node has the token, Patroni will reconfigure all other nodes to use it as the primary. If a replica encounters replay errors, or was a previous primary, Patroni will use pg_rewind, pg_basebackup from the current primary, or even recover from a stored backup to rebuild the node.
That’s something almost none of the other HA tools do. Not only will Patroni promote a replacement primary, but it will rebuild the failed one if it can. If you add a new node to the cluster, it creates the data directory on your behalf based on the cluster configuration. The DCS is the single source of truth Patroni operates from, and in a very real sense, the DCS itself is the cluster.
Things really start to get interesting when the DCS layer itself experiences failures.
Fencing
The idea behind fencing is that a misbehaving node should be decommissioned. The reasoning for this is deceptively simple: in the absence of consensus, you can’t trust any written data. There are many reasons a node could lose contact with the DCS, or the DCS refuses to respond, and none of them matter at all. The safest course of action is to stop Postgres.
If the primary node can’t maintain its ownership of the leadership token, another node seizes it. The Patroni process on that node promotes it to leader, the cluster reconfigures itself around that new primary, and the beat goes on. Isolated replicas don’t have to worry about writes, but they also can’t participate in the leadership race.
An isolated primary knows another node has been promoted in its absence, that it should reject writes to prevent split brain risk, that it should no longer accept new connections. Similarly, a replica cut off from the DCS can’t be monitored, is likely accumulating replication lag, and is otherwise suspect. As a result, Patroni stops the Postgres service on that node.
Believe it or not, most Postgres HA solutions omit this critical factor. Almost all of them will detect a primary failure and promote a standby, but almost none consider what happens if the failure is the network and not the node or Postgres itself. In these systems, an isolated node keeps accepting writes from colocated systems or established connections, keeps operating normally, and doesn’t know or care that a promotion happened elsewhere.
The Postgres service on isolated nodes absolutely must self-terminate, and Patroni ensures that outcome by its very design. Lose contact with the DCS, or if the DCS refuses requests for any reason, shut down. Easy.
Note: One failure scenario for the cluster is that the DCS itself loses quorum. In a five node cluster, a network error could split two nodes from the other three. In such a situation, two nodes lost the majority and will refuse to operate in that state. The Patroni service for any affected nodes doesn't know this, and indeed, it doesn’t matter. The end result is always to stop Postgres.
Routing
The final thing Patroni does to establish a Postgres cluster is manage connection routing. It does this by tracking the ownership of the leadership token and providing an HTTP REST status interface. Any front-end routing system can interrogate a Patroni node for its current state. Whether or not Postgres is online, if the node should be considered writable, if there’s too much replication lag, and so on.
The usual choice for this routing layer is HAProxy as reflected in the architecture diagram, but it could easily be an F5 load balancer, an Amazon ELB, and so on. This determines which connections reach what node—or whether a node should allow connections at all. Users who wish to connect to the Postgres primary simply need to connect to the routing layer. Is it important to connect to a replica that has less than 5MB of replication lag? Routing layer. Patroni evaluates criteria encoded in the health check request and responds accordingly.
Fencing is one half of the equation, and routing control is the other. If Patroni determines a node should not be routable for any reason, it simply returns a failure on the REST interface. A properly configured routing component will then immediately cut any established connections and refuse future routing for that node until it is healthy again.
More importantly, users and applications don’t need to know anything about the node they’re connecting to. In a very real sense, they’re not connecting to a node at all, but the cluster itself. Now, finally, it’s possible to accurately describe Postgres as a cluster of nodes. Each individual node doesn’t actually operate any differently, but Patroni and the underlying DCS establish an underlying fabric that binds everything together.
What about Kubernetes?
Kubernetes solves the problem of truly establishing a Postgres cluster in a similar fashion. Kubernetes operators like CloudNativePG either take the same role as Patroni, or literally use Patroni under the hood like the Crunchy operator. But Kubernetes is a rich ecosystem of inter-operating components with its own design ethos. A Postgres cluster emerges from this design as a consequence of its underlying fundamentals.
Kubernetes isn’t specific to Postgres, and a Postgres HA solution in Kubernetes cannot exist outside of that environment. It is a perfectly valid way to transform Postgres into a cluster, but software outside of a Kubernetes context can’t leverage those capabilities. At least for now, the vast majority of Postgres installations still exist on bare metal, VMs, and other ad-hoc manual deployments.
Final thoughts
Let’s look at MongoDB for a second. The following is a diagram taken directly from their architecture documentation:
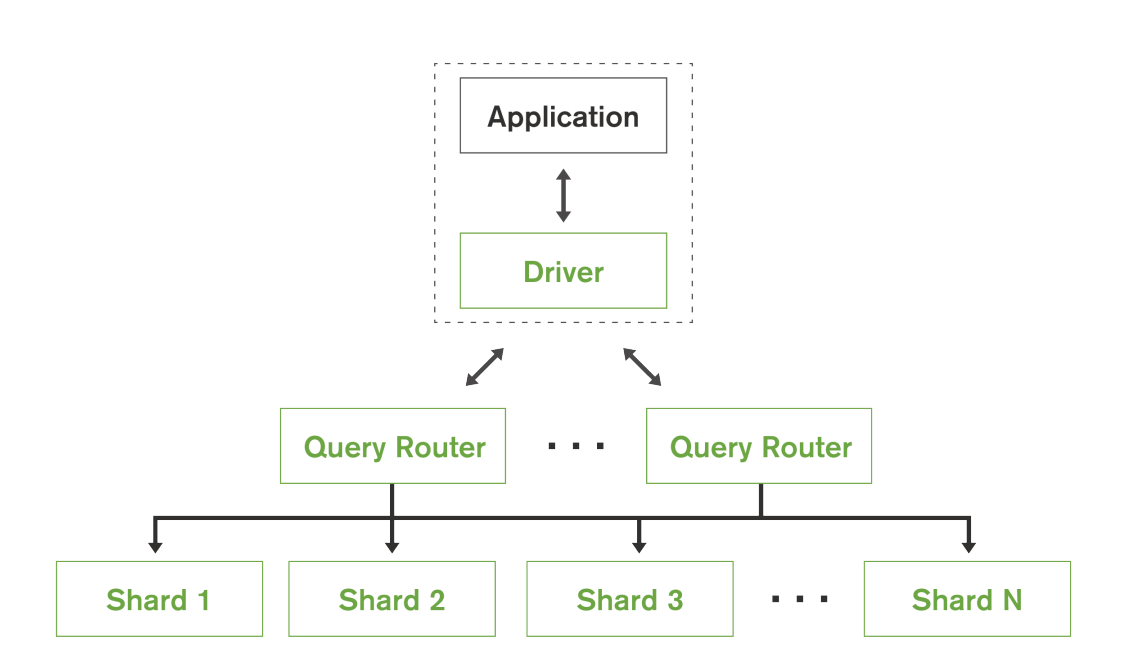 We’re not here to discuss the merits of Postgres versus MongoDB or NoSQL in general. However, look very carefully at this structure. The design manual describes shard architecture in further detail:
We’re not here to discuss the merits of Postgres versus MongoDB or NoSQL in general. However, look very carefully at this structure. The design manual describes shard architecture in further detail:
“If the primary replica for a shard fails, secondary replicas together determine which replica should be elected as the new primary using an extended implementation of the Raft consensus algorithm.”
Does any of this sound familiar? Ignore the sharding aspect for a moment and consider what’s happening here. The cluster has a routing layer and nodes coordinate by consensus through Raft. MongoDB was designed from the very beginning to be a cluster, while Postgres treats node interaction as an afterthought. Outside of extensions like Spock from pgEdge, BDR from EnterpriseDB, or forks like YugabyteDB, every Postgres node is an island. Even Citus, an extension known for using coordinator nodes and data nodes and should be thought of as a cluster, needs Patroni to handle failover between data node replicas.
Postgres simply isn’t a self-organizing cluster without some external orchestration layer. For now, Patroni is the best of these. There’s a reason we use it at pgEdge as part of our Ultra HA architecture. It’s impossible to say what the future might hold, but for now, just use Patroni.

