Introducing ColdFront: Seamlessly Uniting OLTP, Analytics and AI Workloads on PostgreSQL
Our team is excited to announce pgEdge ColdFront v1.0.0-beta1: open-source, transparent data tiering for PostgreSQL that unites OLTP, analytics and AI workloads, with no application code changes required. The headline feature: a fully writable cold tier. Jimmy Angelakos is the lead engineer, and it’s available on GitHub and pgEdge Enterprise Postgres.
Moving aging data off primary PostgreSQL storage is economically obvious. Keeping it fully operational once it’s there is where things get complicated.
The trade-off nobody wants to make
A bank holds seven years of transaction history because regulators say it has to. The table is 4 TB, growing monthly, and the queries that actually touch it hit the last 90 days. Everything older sits in the same PostgreSQL heap, inflating the storage bill, stretching the backup window, and slowing down every VACUUM cycle. The team knows the old data should live somewhere cheaper. They also know that "somewhere cheaper" usually means "somewhere you can't query with the same SQL anymore."
A SaaS platform's compliance team gets a GDPR deletion request. The customer's records span three years. The recent ones delete fine. The older ones were archived to a cold tier six months ago, and that cold tier is read-only. To delete a single customer's data, they have to restore the archived partition back to hot storage, run the delete, re-archive, and re-verify. A one-line SQL statement turned into a half-day ops project.
An AI governance platform is logging every decision trace from autonomous agents across a financial services deployment. The traces are append-heavy and growing fast. Retention is mandatory for regulatory audit. Most of the data is never read again, but when an agent acts on stale information and makes a bad recommendation, the provenance team needs to trace the decision back to the specific source record, correct it, and confirm the correction propagated. If that source record is in a read-only archive, the correction loop breaks.
A growing startup is paying RDS storage rates for 800 GB of event data that drives a dashboard refreshed once a day. The data is valuable for trend analysis. Nobody wants to delete it. But nobody wants to pay $92 a month in storage for data that gets queried once every 24 hours, either.
Four different teams with four different problems. One common thread: PostgreSQL data that's too expensive to keep in primary storage and too important to lose access to.
The options so far all ask you to give something up
The Postgres-lakehouse space has gotten crowded over the past year. Multiple vendors now offer some form of Iceberg integration for PostgreSQL. That's good… but each option is a trade-off.
EDB's Postgres Analytical Accelerator (PGAA) requires EDB's proprietary PostgreSQL distribution and a minimum three-node PGD cluster before you can tier a single table. The cold tier is read-only across all nodes, so correcting archived data means restoring it to the hot heap first. The table access method is proprietary, and the analytical engine (Seafowl) runs as a separate daemon communicating over Arrow Flight RPC.
Databricks Lakebase is a managed-only Neon fork that can't be self-hosted. Cold pages go to S3 in a proprietary chunked format, and open-format access is a one-way mirror to Delta or Iceberg queryable from Photon on the Databricks side, not from PostgreSQL itself.
Snowflake's pg_lake gives you writable Iceberg tables on stock PostgreSQL, which is genuinely good; however the hot and cold tables have different names, your application has to know which one to query, and moving data between them is your job. The stack also loads fifteen-plus extensions with DuckDB running as a separate daemon behind a local socket.
These are real products built by capable teams, and each solves part of the problem. But each also asks you to give something up that matters in production: your PostgreSQL distribution, your ability to self-host, your ability to write to cold data, or the transparency that lets your application not care about tiers.
ColdFront doesn't ask
pgEdge ColdFront is a transparent data tiering and partition lifecycle management system for PostgreSQL. It entered beta this week. Here's what it does without asking you to trade anything for it.
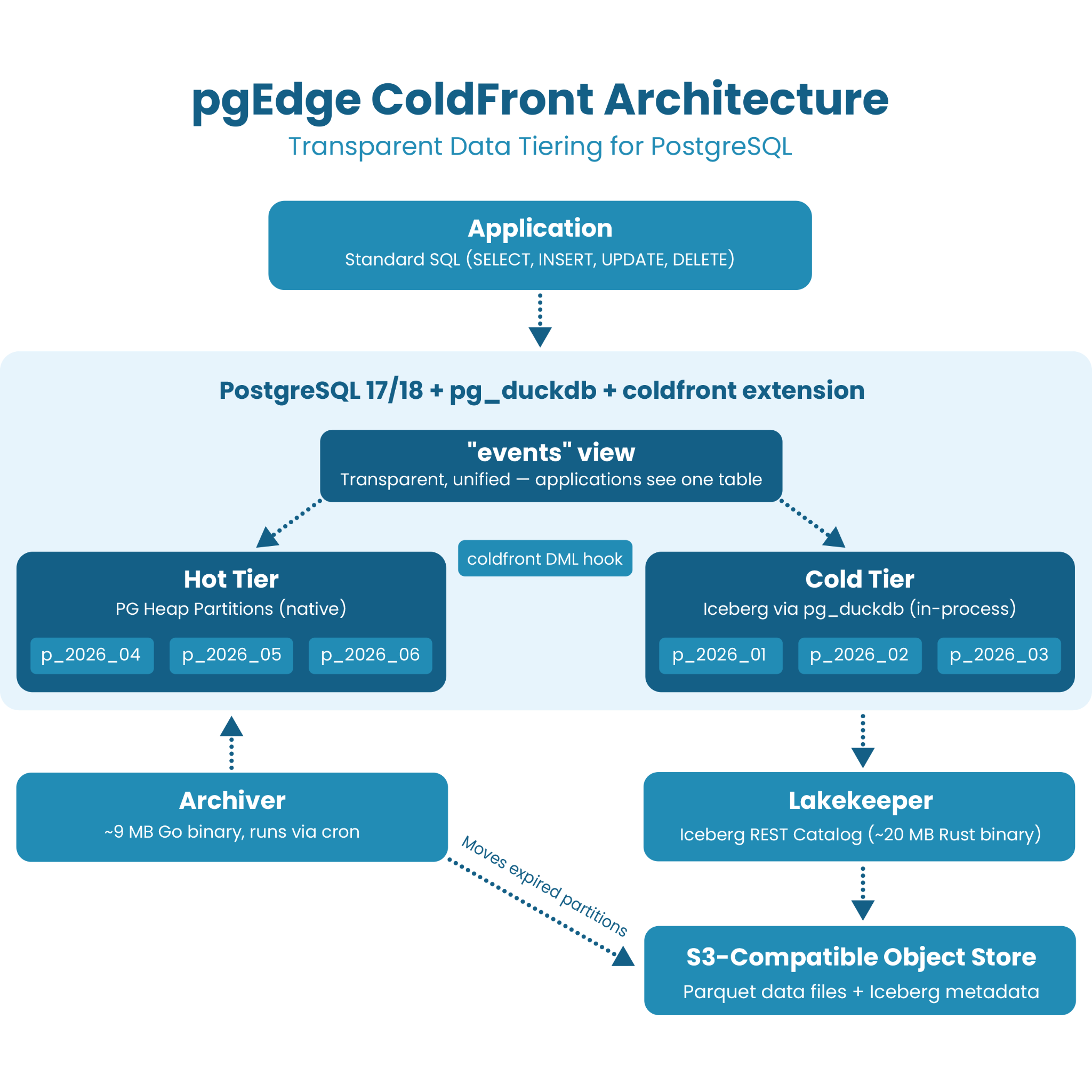 Stock upstream PostgreSQL. ColdFront runs on PostgreSQL 17 and 18 from the standard community distribution packages, the same PostgreSQL your team installed from apt or yum, operated with pg_dump, logical replication, and whatever monitoring you already use. Two extensions load at startup (pg_duckdb for in-process Iceberg I/O, coldfront for the DML rewrite hook), and nothing below the extension layer is modified. It's the PostgreSQL that ships with every Linux distribution, not a proprietary fork.
Stock upstream PostgreSQL. ColdFront runs on PostgreSQL 17 and 18 from the standard community distribution packages, the same PostgreSQL your team installed from apt or yum, operated with pg_dump, logical replication, and whatever monitoring you already use. Two extensions load at startup (pg_duckdb for in-process Iceberg I/O, coldfront for the DML rewrite hook), and nothing below the extension layer is modified. It's the PostgreSQL that ships with every Linux distribution, not a proprietary fork.
Writable cold tier. UPDATE and DELETE work on archived rows through the same table name, so a GDPR deletion request is one SQL statement rather than a restore-delete-rearchive cycle. Operators who prefer read-only cold storage can enforce it with a single Grand Unified Configuration (GUC), but the writable model is the default because real-world data needs corrections, and corrections shouldn't require an ops project.
Distributed cold writes. On a pgEdge Spock mesh, ColdFront's bakery protocol (model-checked in TLA+, built on Lamport/Ricart-Agrawala) serializes Iceberg commits across nodes so multiple PostgreSQL nodes write to the same Iceberg table concurrently with no 409 conflicts and no application-level retry. Competing approaches that integrate with distributed PostgreSQL replicate hot writes across nodes but make the cold tier read-only everywhere, so ColdFront is the only option where any node in the mesh can write to archived data directly. Validated on Spock clusters with one writer per node, throughput scaled from 2.4M rows/sec on 3 nodes to 3.8M on 4 and 4.2M on 5.
One table name. Applications use SELECT, INSERT, UPDATE, and DELETE against the same relation they always have. A C extension intercepts DML at the planner level and routes each operation to the correct tier. DuckDB runs in-process inside PostgreSQL as a library call (not a separate daemon, not over RPC) for columnar-engine analytical performance on cold Parquet data. The application doesn't know there are two tiers, and it doesn't need to. Teams query operational and historical data simultaneously through the same SQL - no separate analytics system, no ETL pipeline, no glue code.
Partition lifecycle as a standalone capability. ColdFront manages the full cycle: pre-creating future partitions, tiering aged data to Iceberg, expiring cold data past retention. The full hot-to-cold-to-expired lifecycle runs by policy on cron. It also works without a cold tier at all, as a pure partition manager on stock PostgreSQL. It supports single-column primary keys on time-partitioned tables (via snowflake or UUIDv7 id mode, solving a long-standing PostgreSQL partitioning pain) and 2-level tenant-by-time sub-partitioning. Both are limitations in competing approaches that require proprietary cluster managers.
Open formats, no lock-in. Cold data is Apache Iceberg (Parquet files on any S3-compatible store) using the standard Iceberg REST catalog protocol via Lakekeeper. If you stop using ColdFront, your cold data is still standard Iceberg readable by any Iceberg-capable tool, and your hot data is still a PostgreSQL table. Nothing on disk requires ColdFront to read. And because ColdFront runs on stock upstream PostgreSQL, there is nothing to migrate to - if your team already runs PostgreSQL, you are already on the right database.
The data layer underneath AI governance
The agent governance and provenance market is not hypothetical anymore. Galileo, Arize, LangSmith, Patronus, Arthur, BigID, and IBM's watsonx.governance are all shipping products that track what AI agents do, what data they access, and whether their decisions stay within policy. The frontier model providers themselves are moving into workflow management and agent orchestration as model performance improvements plateau. The governance infrastructure around those agents is becoming as important as the agents themselves.
All of these platforms generate data that follows the same pattern: append-heavy writes, mandatory retention for compliance, infrequent reads, and the need to correct data at source when something goes wrong. That's ColdFront's exact workload profile. Agent decision traces tier from hot to cold automatically. When a provenance investigation traces a bad agent decision back to a stale source record in the cold tier, the writable cold tier lets the team correct it with a standard UPDATE with no restore-to-hot round-trip, and the correction is immediate and auditable.
Context assembly tools (the "context architecture" pattern replacing simple RAG pipelines) query across recent and historical data in the same operation to compile agent context windows. ColdFront's unified view serves both tiers through one table name and one SQL query. DuckDB gives columnar speed on the historical portion. Hot-tier partition pruning gives index speed on the recent portion. The context assembler gets both in one round-trip and doesn't need to know tiers exist.
The EU AI Act requires governance of data quality, provenance, and sensitivity before AI deployment. The infrastructure to meet that requirement generates exactly the kind of data ColdFront was built to manage.
Try it
ColdFront beta is available now on GitHub under the PostgreSQL License. Both operating modes work end-to-end with a fully green CI matrix across vanilla and mesh topologies, including physical standby reads - a tested, production-grade beta, not a tech preview. The quickstart is a docker-compose file that brings up PostgreSQL, Lakekeeper, and SeaweedFS in one command. Documentation and reference architectures are at https://docs.pgedge.com/coldfront.
ColdFront is a component of pgEdge Enterprise Postgres. Enterprise support, distributed cold writes via Spock, and the full pgEdge toolkit (Agentic AI Toolkit - MCP Server, RAG Server, Vectorizer, and Docloader - plus DBA Workbench) are included with an Enterprise subscription. The open source components are usable standalone on community PostgreSQL.
Stock PostgreSQL versions 16, 17, and 18 are fully supported. Storage types supported include S3-compatible, Google Cloud Storage, and Azure Blob Storage (ADLS Gen2).

