RAG With Transactional Memory and Consistency Guarantees Inside SQL Engines
Most RAG systems were built for a specific workload: abundant reads, relatively few writes, and a document corpus that doesn't change much. That model made sense for early retrieval pipelines, but it doesn't reflect how production agent systems actually behave. In practice, multiple agents are constantly writing new observations, updating shared memory, and regenerating embeddings, often at the same time. The storage layer that worked fine for document search starts showing cracks under that kind of pressure.
The failures that result aren't always obvious. Systems stay online, but answers drift. One agent writes a knowledge update while another is mid-query, reading a half-committed state. The same question asked twice returns different answers. Embeddings exist in the index with no corresponding source text. These symptoms get blamed on the model, but the model isn't the problem. The storage layer is serving up an inconsistent state, and no amount of prompt engineering can fix that.
This isn't a new class of problem. Databases have been solving concurrent write correctness for decades, and PostgreSQL offers guarantees that meet those agent memory needs.
 What RAG Systems Are Missing Today
What RAG Systems Are Missing Today
RAG systems depend on memory that evolves over time, but most current architectures were designed for static document search rather than stateful reasoning, creating fundamental correctness, consistency, and reproducibility problems in production environments.
Stateless Retrieval Problems and Solutions
Most RAG pipelines treat retrieval as a stateless search over embeddings and documents. The system pulls the top matching chunks with no awareness of how memory has evolved, what the agent's current session context is, or where a piece of information sits on a timeline. For static document search, that limitation rarely matters. For agent memory, where knowledge changes continuously, it is a real problem.
Without stateful awareness, retrieval starts mixing facts from different points in time. One query might retrieve yesterday's policy while another surfaces today's update. The model receives both, treats them as equally current, and produces answers that are inconsistent in ways that are hard to catch and harder to explain. Reproducibility breaks down, and agents start reasoning from a knowledge state that never existed as a coherent whole.
Memory Corruption Under Concurrent Agent Writes
Multi-agent systems create another layer of risk. When several agents write to shared memory at the same time, without transactional control, those writes can collide or partially complete. One agent might update metadata while another is updating embeddings. If something fails between those two operations, the memory lands in a broken state. Retrieval might return embeddings with no source text, or source text with no corresponding vector index entry.
Under high load, write ordering becomes unpredictable. The troubling part is that these failures tend to be silent: no error is thrown, and the system quietly returns corrupted data. PostgreSQL-style transactions close this gap by treating related writes as a single atomic operation, so memory is either fully written or not written at all.
Lack of Auditability and Replay
Most RAG systems only store where memory ended up, not how it got there. When an agent produces a wrong answer, teams have no way to reconstruct which version of memory was active at the time, what the retrieval looked like, or which update introduced the problem. For compliance-sensitive environments, that missing history is a serious liability.
Enterprises need full lineage, from source document through embedding generation to final response. Security teams need forensic replay and ML teams need to reproduce model behavior across time. Write-ahead logging addresses this directly by recording every memory mutation in sequence, creating a durable, ordered log that supports both debugging and audit.
External Vector Store Consistency Limitations
External vector stores are built to maximize similarity search throughput, and transactional correctness is not their priority. Many operate on eventual consistency, with asynchronous index updates and best-effort durability guarantees, which means a retrieval call under concurrent writes might return stale embeddings or miss recent updates entirely. Cross-region replication adds further lag.
For pure search workloads, these tradeoffs are reasonable. For agent memory, where a single outdated fact can change a decision, they are not. Running vector retrieval inside PostgreSQL keeps embeddings, metadata, and relational context committed together, so what the agent retrieves is always a coherent, synchronized snapshot.
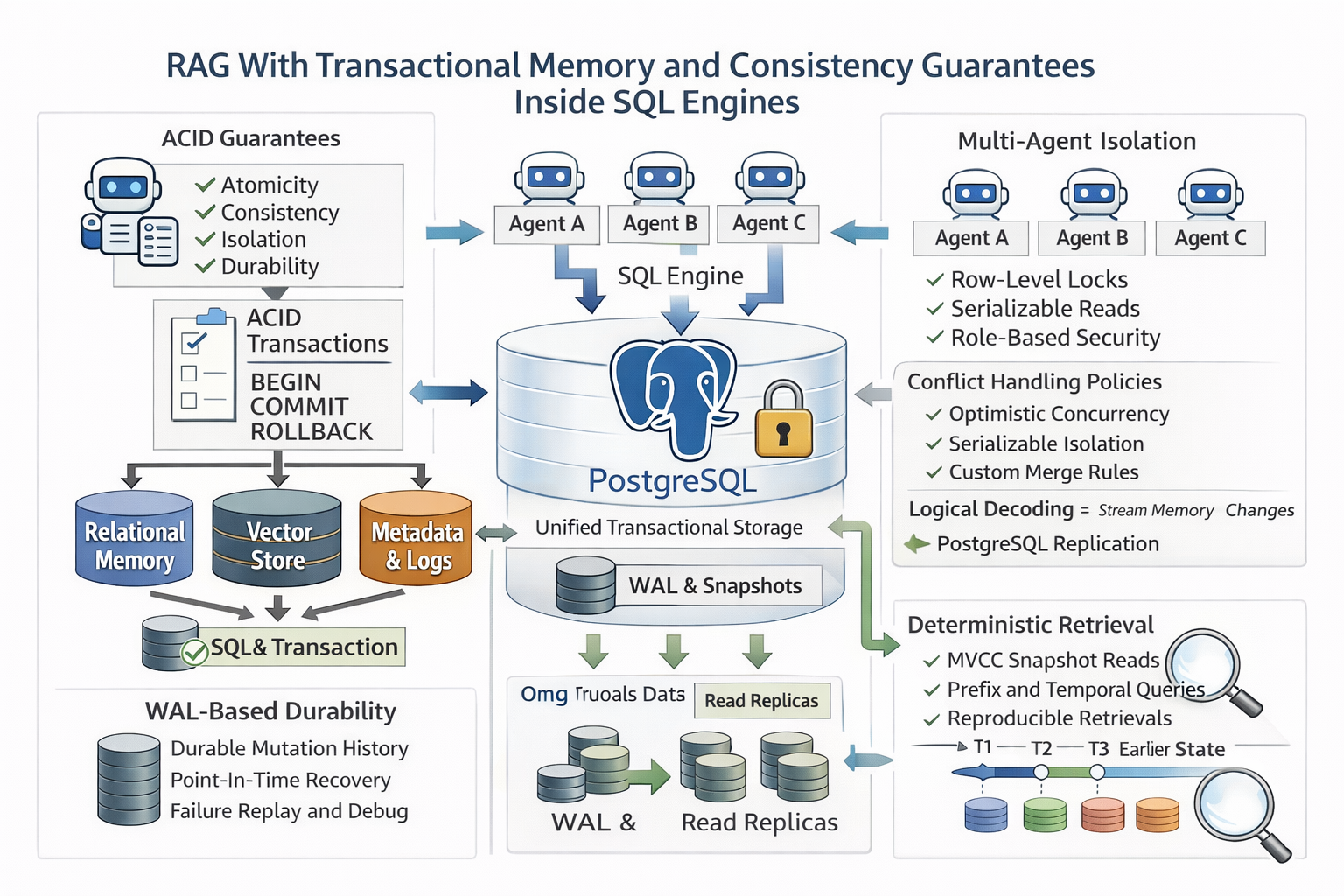
PostgreSQL as a Transactional RAG Memory Engine
PostgreSQL maps these guarantees onto agent memory directly. Memory writes open inside BEGIN and COMMIT boundaries, so embeddings, metadata, and session state always commit together as one unit. If the system crashes mid-write, the transaction rolls back automatically. Partial memory states never become visible to queries, and silent corruption is structurally prevented.
The Postgres storage model provides everything a memory layer needs. Relational tables enforce constraints between memory objects, JSON columns hold flexible schema-free payloads, and vector columns support semantic similarity retrieval. Hybrid queries combine all three in a single pass, filtering by structured metadata while ranking by semantic relevance, which improves precision over pure vector search.
Access control is built into a PostgreSQL deployment. Role-based permissions isolate agents and tenants from each other, and row-level security enforces visibility at the data layer rather than the application layer. The same infrastructure that protects a multi-tenant database protects a multi-agent memory environment, with no additional tooling required.
 Transactional Agent Memory Architecture
Transactional Agent Memory Architecture
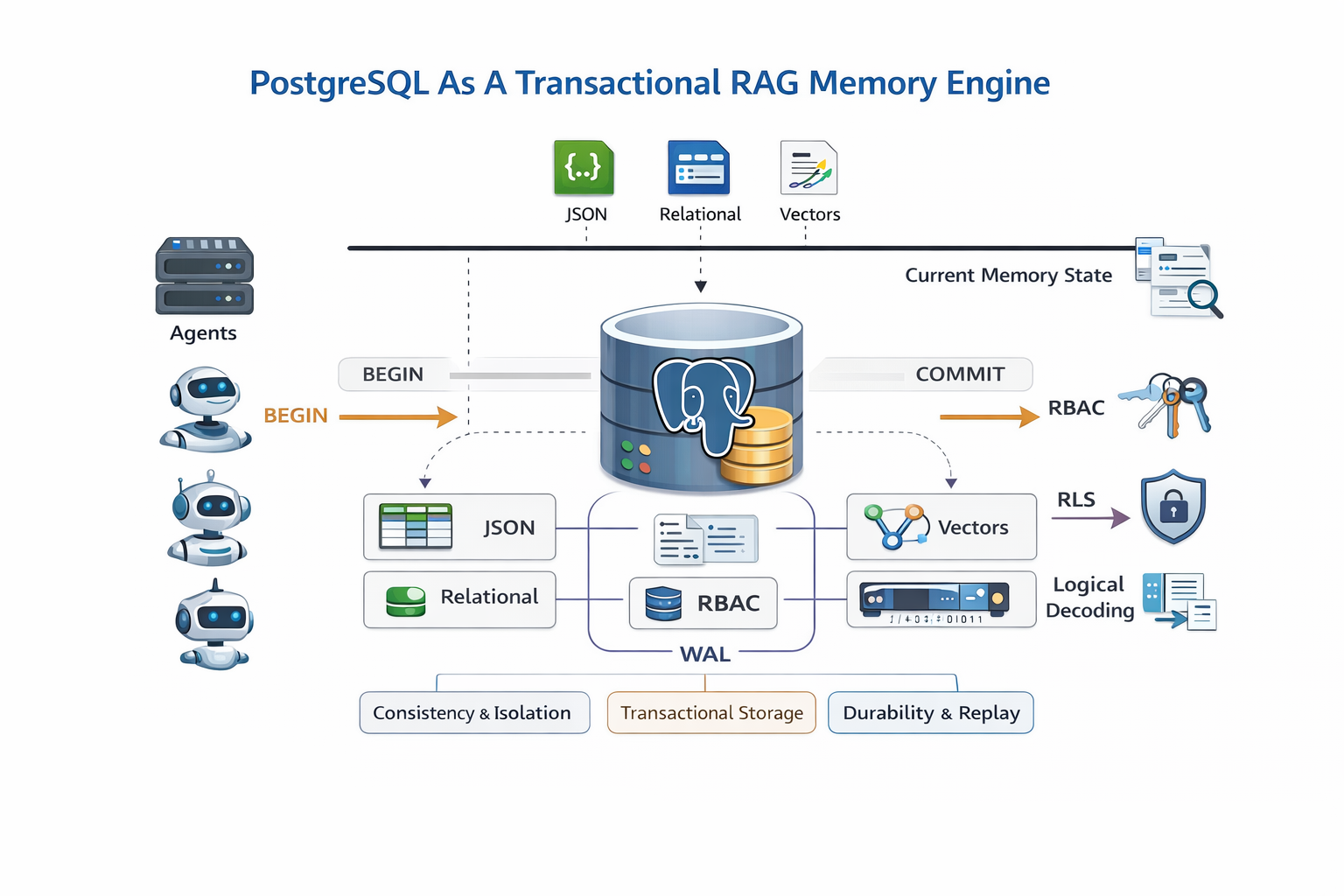
The most reliable way to build agent memory is to treat it as an event-driven stream of mutations rather than a simple state store. Each memory event captures the actor, timestamp, operation type, and payload, so the record tells you not just what changed but why it changed. That distinction matters when something goes wrong — instead of trying to reconstruct a decision from a final state, engineers can replay the exact sequence of events that led to it, shifting debugging from inference to evidence.
Embedding storage needs a firm connection to its source. Embedding tables that reference source text through foreign keys allows the database engine to enforce referential integrity automatically, which means orphaned vectors become structurally impossible rather than just unlikely. Embeddings always reflect the state of their source rows, and retrieval quality stays stable because the consistency is enforced at the engine level, not the application level.
Session state tracking closes another common gap. Storing context windows, task states, and reasoning checkpoints in session tables means an agent can resume exactly where it left off after a restart, without recomputing anything. Long-running workflows stop being fragile, and infrastructure failures become recoverable interruptions rather than unrecoverable resets.
Writing across multiple tables within a single transaction is what ties all of this together. A memory update that touches embeddings, metadata, and session state either completes fully or leaves the database completely unchanged. There is no intermediate state or partial write that a concurrent agent might read and act on. Under high concurrency, memory relationships stay intact because the commit boundary enforces it.
WAL-based recovery makes failure handling predictable. On restart, only committed memory mutations are replayed. Partial writes from transactions that never completed simply do not appear in the recovered state. Recovery time stays consistent regardless of what the system was doing when it went down, which means failure is a bounded, manageable event rather than an unpredictable one.
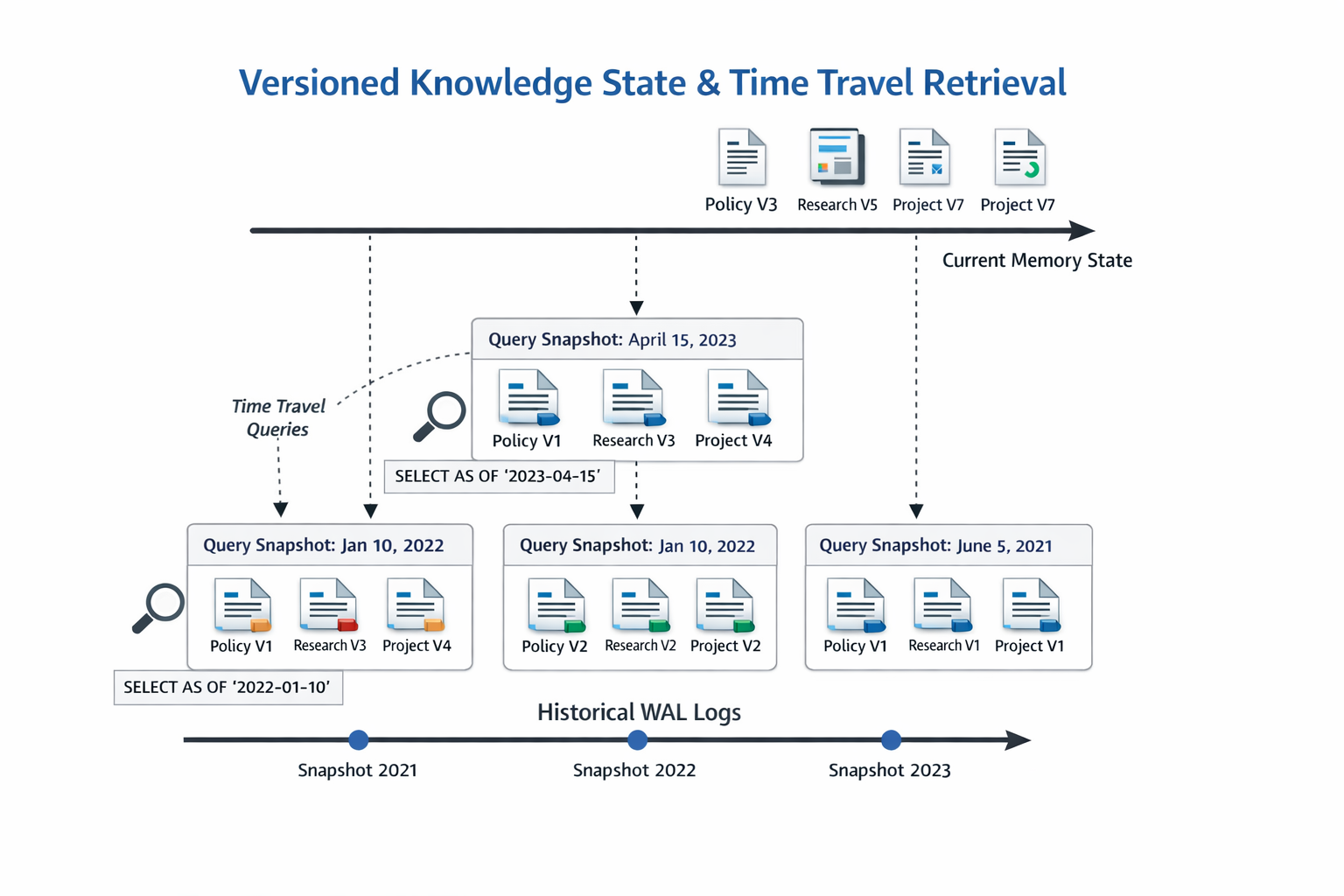
Versioned Knowledge State And Time Travel Retrieval
Point-in-time queries give agents a consistent view of memory tied to a specific transaction timestamp, which means retrieval results stay stable across execution retries and do not shift mid-reasoning as other agents write new data. For compliance teams, this same capability supports audit replay, allowing you to reconstruct exactly what the knowledge base looked like at any moment in the past and verify the information an agent was working with when it made a decision. Financial and healthcare systems already depend on this kind of verifiable historical state; the mechanism in PostgreSQL powers those production workloads effortlessly.
 Multi-Agent Memory Consistency and Conflict Resolution
Multi-Agent Memory Consistency and Conflict Resolution
Shared memory under high concurrency is where things get complicated. When multiple agents write simultaneously without locking or version control, they can quietly overwrite each other's work. Vector-only systems make this worse because the data loss is silent, with no error or warning, just a corrupted memory state that surfaces later as a bad answer.
Row-level locking addresses the most critical updates by serializing writes only where necessary, leaving everything else to run in parallel. The result is strong consistency without a meaningful throughput penalty. Where contention is frequent but not universal, optimistic concurrency offers another path: version columns detect write conflicts at commit time, and applications retry failed writes cleanly. This pattern is already standard in high-concurrency enterprise systems for good reason.
Where the stakes are highest, serializable isolation removes the subtler failure modes like phantom reads and write skew. Trading systems have long depended on these guarantees, and agent planning workflows carry the same need for predictable, conflict-free reads. When logical conflicts do occur, application-level merge policies resolve them through defined business rules, whether agent priority rankings or timestamp-based logic, keeping resolution deterministic and auditable.
Hybrid Retrieval Inside PostgreSQL
Running vector similarity search inside SQL execution plans changes what retrieval can do. pgvector brings HNSW and IVF index support directly into PostgreSQL, so semantic search runs inside transactional boundaries rather than outside them, keeping memory consistency enforced during the search itself.
Hybrid queries push this further by combining semantic similarity with relational filters in a single pass. A query can restrict results by tenant, time window, or classification while simultaneously ranking by vector similarity, which improves retrieval precision and reduces hallucination rates compared to pure vector search. Tenant-scoped boundaries enforce isolation at the query level, eliminating cross-tenant leakage by design, while temporal filters restrict retrieval to knowledge that was valid during the agent's session window, stabilizing answers across long-running workflows.
Streaming RAG Using Database Change Streams
WAL decoding turns memory mutations into a native event stream without requiring a separate message broker, which removes an entire layer of infrastructure and the failure modes that come with it. In practice, embedding generation happens asynchronously: source text and metadata commit transactionally, then a downstream worker picks up the change event and generates the embedding. This means there is a short window where the source text is committed but the embedding has not caught up yet.
This is a deliberate tradeoff, because calling an external embedding model synchronously inside a transaction would add hundreds of milliseconds to every write, which is impractical at any real volume. The important difference from pure vector-store architectures is that this inconsistency is bounded and visible. You can query exactly which rows are missing embeddings, the source text itself is already durably committed, and the gap closes predictably. It is eventual consistency with guardrails, not silent corruption.
Operations, Observability, and Correctness
Running the RAG memory layer inside PostgreSQL means inheriting a mature operational ecosystem: read replicas, partitioning, connection pooling, audit logging, and query metrics. Teams scaling agent memory inherit all of it without building or maintaining a separate system. Audit trails make every memory change traceable, and query-level metrics covering recall, latency, and filter selectivity give teams measurable data to tune against, turning performance work from guesswork into evidence.
Transactions eliminate partial writes, and row locking ensures concurrent writes resolve without overwriting each other. Snapshot reads guarantee queries never mix knowledge from different commit states, while foreign key constraints make orphaned embeddings structurally impossible. Row-level security handles cross-tenant isolation at the engine level, removing the need for application-layer guards.
Database-native RAG Solves Problems
Transactional memory is the foundation of reliable agent RAG systems. Atomicity and isolation eliminate the partial writes, concurrent overwrites, and mixed-state reads that cause memory to drift and answers to become unreliable. That doesn't make the model itself deterministic, since temperature, floating point variance, and prompt sensitivity all affect output in ways no storage layer can control. What it does mean is that the memory your agents reason from is consistent and trustworthy. That is the part PostgreSQL fixes, and it is the part that matters most at scale.
Migration from vector-only RAG systems starts with moving metadata and embeddings into PostgreSQL. The next step is to introduce transactional memory writes, with an ultimate goal of integrating the agent runtime directly with the database's native memory control.
Need a hand getting started with performing retrieval-augmented generation of text based on content from a PostgreSQL database, using pgvector? The pgedge-rag-server (hosted on GitHub) might be worth checking out. Give the project a star while you're there to keep an eye out for future releases, and feel free to get in touch with our team — anytime — if you have any questions.

