Volatile Queries and Semantic Caching: How to Make Sure It Always Returns the Right Answer
Part 3 of the Semantic Caching in PostgreSQL series. Part 1 covers the fundamentals of pg_semantic_cache — how it stores query embeddings, runs cosine similarity searches via pgvector, and returns cached LLM results without a round-trip to your model provider. Part 2 goes deeper into production operations: cache tags, eviction policies, monitoring, and Python integration patterns. This post focuses on a specific class of queries that need to be handled differently, and where that handling belongs.
A well-tuned semantic cache can deliver 60–80% fewer LLM API calls and matching cost savings. But those numbers depend on caching the right queries. Cache everything and you risk returning answers that were accurate once but are no longer true — and returning them confidently, with no indication that anything is wrong. Understanding the line between cacheable and non-cacheable queries, and owning that line in the right layer of your stack, is what separates a semantic cache that saves money from one that quietly misleads users.
The Two Kinds of Queries Your Cache Will See
Every query that arrives at your application falls into one of two buckets.
Time-invariant queries have answers that do not depend on when they are asked. "What is the boiling point of water?" is the same answer today as it was last year and will be next year. "Explain how TCP/IP works." "What does idempotent mean?" Semantic caching is a natural fit for these — one LLM call populates the entry, and every paraphrase that follows is a free hit.
Volatile queries have answers that are bound to the moment they are asked. Their correct response changes with time, live state, or the specific user asking:
"What is the current time?"
"What time is it right now?"
"What's today's date?"
"What is the current stock price of Apple?"
"What's the weather like right now?"
"What are the latest breaking news headlines?"
"What's my current account balance?"
The defining property of volatile queries is that they produce stable embeddings but changing answers. Ask "What is the current time?" at 14:00 and again at 14:05 and the two vectors have cosine similarity of 1.0 — the same sentence, the same semantics, an identical embedding. But one correct answer is 14:00 and the other is 14:05. A cache that stores the first call and serves it for subsequent matches will confidently return the wrong answer forever — and the similarity score will be a perfect 1.0 each time, giving no indication that anything is stale.
Now add paraphrases into the mix. "What time is it right now?" and "Can you tell me the current time?" and "What's the time?" all map to nearby positions in vector space — similarity scores above 0.90 are typical. Every one of them should reach the LLM directly, never the cache.
The Cache Is Doing Its Job Correctly
Here is the important framing: when pg_semantic_cache returns a stored result for a volatile query, it is not making a mistake. The vector geometry is accurate. The similarity score is legitimate. The cache found the closest matching entry above the configured threshold and returned it. That is precisely what a semantic cache is designed to do.
The issue is not the cache's behavior — it is the assumption that every query should go through the cache in the first place. That assumption is the application's to make, not the cache's.
Asking pg_semantic_cache to distinguish volatile from non-volatile queries would require it to understand the relationship between a query's meaning and time. It would need to know that "current time" implies a result that expires in seconds, while "speed of light" is valid indefinitely. That is semantic reasoning about a query's temporal context — something the application layer possesses and the cache does not.
pg_semantic_cache stores vectors, finds similar vectors, and returns results. Deciding which queries are worth caching is the application's job, and it turns out the application is perfectly equipped for it.
Why Query Classification Belongs in the Application
Well-architected systems assign each responsibility to the layer best equipped to fulfill it. Let's map that to a semantic caching stack:
| Layer | Responsibility |
|---|---|
| Embedding model | Convert query text to a vector |
| pg_semantic_cache | Store vectors, find similar vectors, return results |
| Application | Decide which queries are worth caching |
The application layer has context that neither the embedding model nor the cache possesses.
It knows the domain. A financial trading application knows that stock prices are real-time data. A customer support bot knows that "what is my order status?" is user-specific and non-cacheable. A weather service knows that any query mentioning "right now" or "currently" needs a live answer. The cache knows none of this — and it shouldn't need to.
It knows the user's intent. The application can inspect query metadata, session context, feature flags, or user-provided parameters to make routing decisions that go well beyond what any pattern in the query text can express.
It controls the flow. The application already decides when to call the embedding model, when to query the cache, and when to invoke the LLM. Volatile detection sits naturally in this orchestration logic. Adding one classification step before the cache lookup costs microseconds and eliminates an entire category of incorrect behavior.
Embedding this classification logic into the cache itself would couple a general-purpose infrastructure component to domain-specific knowledge it has no business knowing. Your cache should be reusable across applications. Your routing logic is specific to yours.
The Decision Flow
Once the application takes ownership of query classification, the pipeline becomes clean and explicit. Volatile queries are intercepted before any embedding is computed or any database round-trip is made:
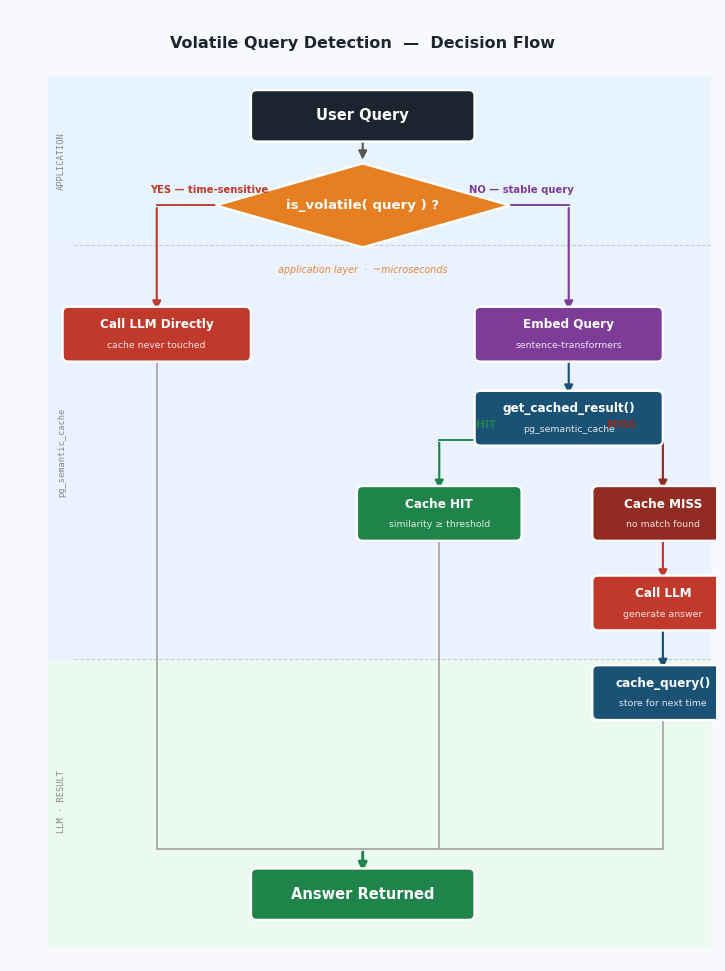 Each layer does what it does best. The application classifies. The cache stores and retrieves. Neither is asked to do the other's job.
Each layer does what it does best. The application classifies. The cache stores and retrieves. Neither is asked to do the other's job.
Building the Classifier
Regex: the fast path for known domains
For most applications, the set of volatile query patterns is knowable in advance. A regex classifier handles them with negligible overhead — well under a microsecond per query, zero external calls:
import re
VOLATILE_PATTERNS = [
r"\bwhat.{0,10}time\b", # "what time is it", "what's the time"
r"\bcurrent\s+time\b",
r"\bright\s+now\b",
r"\btoday.{0,10}date\b", # "today's date", "what is today's date"
r"\bcurrent\s+date\b",
r"\blatest\s+news\b",
r"\bbreaking\s+news\b",
r"\bcurrent\s+(weather|temperature|price|stock|rate|score)\b",
r"\bweather\b.{0,15}\b(today|now|currently)\b",
r"\bstock\s+price\b",
r"\blive\s+(score|update|feed|result)\b",
r"\bmy\s+(location|ip\s+address|position)\b",
]
_volatile_re = re.compile("|".join(VOLATILE_PATTERNS), re.IGNORECASE)
def is_volatile(query: str) -> bool:
"""Return True when the query's correct answer changes with time."""
return bool(_volatile_re.search(query))Start with this. It is deterministic, auditable, and fast.
LLM classifier: coverage for open-ended inputs
If your application accepts free-form user input and you expect volatile patterns you haven't anticipated, a lightweight LLM pre-classifier catches what the regex misses:
def is_volatile_llm(query: str) -> bool:
"""Use a fast LLM call to classify before any cache interaction."""
response = llm.complete(
"Does answering this question correctly require real-time or "
"live data? Answer yes or no only.\n\nQuestion: " + query
)
return response.strip().lower().startswith("yes")In practice: use the regex classifier in production, use the LLM classifier during development to discover new volatile patterns, and fold those discoveries into the regex list over time.
The Complete Python Integration
Now let's put it together. Here is the full pipeline using pg_semantic_cache's SQL functions. The application owns steps 1 and 2. The extension owns steps 3 and 4.
import json
import psycopg2
from psycopg2.extras import RealDictCursor, Json
from sentence_transformers import SentenceTransformer
SIMILARITY_THRESHOLD = 0.80 # tune per your domain
DEFAULT_TTL = 3600 # seconds; adjust per query type
def process_query(conn, model, query: str) -> str:
# Step 1 — classify: volatile queries skip the cache entirely
if is_volatile(query):
return llm_answer(query)
# Step 2 — embed: only reached for non-volatile queries
embedding = model.encode(query).tolist()
emb_lit = "[" + ",".join(f"{v:.6f}" for v in embedding) + "]"
# Step 3 — cache lookup via pg_semantic_cache
with conn.cursor(cursor_factory=RealDictCursor) as cur:
cur.execute(
"""
SELECT found, result_data, similarity_score
FROM semantic_cache.get_cached_result(
%s::text, -- query embedding
%s::float4, -- similarity threshold
NULL -- no max-age constraint
)
""",
(emb_lit, SIMILARITY_THRESHOLD),
)
row = cur.fetchone()
if row and row["found"]:
# Cache hit — LLM call saved, return immediately
print(f"Cache HIT (similarity={row['similarity_score']:.3f})")
return str(row["result_data"])
# Step 4 — cache miss: call LLM, store result for next time
result = llm_answer(query)
with conn.cursor() as cur:
cur.execute(
"""
SELECT semantic_cache.cache_query(
%s::text, -- original query text
%s::text, -- embedding
%s::jsonb, -- result to cache
%s, -- TTL in seconds
ARRAY[]::text[] -- optional tags
)
""",
(query, emb_lit, Json(result), DEFAULT_TTL),
)
conn.commit()
print(f"Cache MISS — result stored")
return resultThe volatile check in step 1 is the only difference from a naive cache-everything approach. One function call, zero database round-trips, complete protection against stale volatile answers.
Seeing It in Action
The pg_semantic_cache repository includes a complete runnable example at examples/volatile_query_detection/ that demonstrates all three outcomes — volatile bypass, cache miss, and cache hit — using real LLM calls.
The stack:
PostgreSQL 18 via pgedge packages, with
pg_semantic_cachebuilt from sourcesentence-transformers(all-MiniLM-L6-v2, 384-dim vectors) for embeddingsOllama (
llama3.2:1b) for LLM generation — no API key required
cd examples/volatile_query_detection
docker compose up --buildVolatile queries: LLM called directly, cache never touched
Query : 'What is the current time?'
Decision: VOLATILE — calling LLM directly, skipping cache
Result : I'm not currently able to share the time... (2.46s)
Query : "What's the current weather like?"
Decision: VOLATILE — calling LLM directly, skipping cache
Result : I don't have real-time access to your location... (2.43s)
Query : 'What is the current stock price of Apple?'
Decision: VOLATILE — calling LLM directly, skipping cache
Result : I don't have access to real-time market data... (3.26s)get_cached_result() and cache_query() were never called. The cache was not involved — which is exactly correct.
Non-volatile queries: first ask hits the LLM, result stored
Query : 'What is the capital of France?'
Decision: CACHE MISS — calling LLM…
Result : The capital of France is Paris... (2.62s, stored in cache)
Query : 'What is the speed of light?'
Decision: CACHE MISS — calling LLM…
Result : approximately 299,792 km/s... (2.32s, stored in cache)Semantically similar rephrases: cache returns the stored answer
Query : "What's the capital city of France?"
Decision: CACHE HIT (similarity=0.957) — LLM call saved
Result : The capital of France is Paris...
Query : 'How fast does light travel?'
Decision: CACHE HIT (similarity=0.832) — LLM call saved
Result : approximately 299,792 km/s...
Query : 'What is 2+2?'
Decision: CACHE HIT (similarity=1.000) — LLM call saved
Result : Two plus two equals four...End-to-end statistics
Cache entries : 5
Cache hits : 6 ← 6 LLM calls saved entirely
Cache misses : 5
Volatile queries skipped : 6 ← 6 queries bypassed cache, got live answers
Hit rate (non-volatile) : 55%The 55% hit rate is a cold-start result — each stable question was asked once before its rephrased equivalent arrived. In a production system with a warm cache and a large question population, the hit rate climbs substantially. The important number is the volatile count: 6 queries that would have returned wrong cached answers instead reached the LLM and returned correct live responses.
How the Rest of the Ecosystem Handles This
This is not a design choice unique to pg_semantic_cache. Surveying the major semantic caching products across the LLM ecosystem reveals a consistent pattern: not one of them performs automatic volatile detection internally. Every product delegates this decision to the application.
GPTCache
GPTCache (Zilliz) is the most feature-rich open-source semantic cache for LLMs, and it goes furthest in providing integration points for volatile handling. It offers three mechanisms.
Per-request skip flag — pass cache_skip=True to bypass both lookup and storage for a single call:
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "What time is it?"}],
cache_skip=True
)Global pre-processing hook — cache_enable_func in cache.init() accepts a callable that inspects every request and returns False to skip all cache logic. The function receives the raw LLM call arguments, so you extract the query text from wherever it appears in those args:
def skip_volatile(*args, **kwargs) -> bool:
# args/kwargs are the raw OpenAI call arguments
query = kwargs.get("prompt", "")
if not query:
messages = kwargs.get("messages", [])
query = " ".join(m.get("content", "") for m in messages)
volatile = ["current time", "right now", "today's date",
"weather", "stock price", "breaking news"]
return not any(p in query.lower() for p in volatile)
cache.init(cache_enable_func=skip_volatile, ...)Temperature-based bypass — GPTCache intercepts the temperature parameter and uses it probabilistically to control cache behavior. At temperature=2.0 the cache is always skipped; at temperature=0 it is always consulted. This lets callers signal volatility through an existing LLM parameter with no extra API surface.
Notice what GPTCache is doing: it is building clean hooks into which the application plugs its own logic. The classification itself — which queries are volatile — is still entirely the developer's responsibility. The hooks just make it easier to act on that classification at the right point in the lifecycle.
LangChain Semantic Cache
LangChain's semantic cache backends (InMemorySemanticCache, CassandraSemanticCache, RedisSemanticCache) expose no skip mechanism at all. The BaseCache interface — which defines lookup(), update(), clear(), and their async counterparts — contains no hook, per-request flag, or bypass parameter for volatile queries.
The community workaround is the same explicit application-layer conditional:
if is_volatile(query):
response = llm.invoke(query) # cache not involved
else:
response = chain.invoke(query) # normal cache-first pathA feature request for built-in per-query cache bypass has been open in the LangChain repository for some time — confirming this is a recognized gap that the library itself has not addressed. The application-layer conditional is considered the correct pattern in the meantime.
Redis (RedisVL / LangCache)
RedisVL's SemanticCache and Redis's managed LangCache service both support per-entry TTL overrides as the closest they come to volatile-aware handling:
cache.store(
prompt="What is the current weather in London?",
response=response,
ttl=60 # 60 seconds instead of the global default
)Redis's own engineering blog recommends adaptive TTL values: 15–30 minutes for stock prices and weather, longer for stable facts. This is good advice — but TTL-based expiry reduces the window of staleness rather than eliminating it. A cached stock price from 14 minutes ago is still wrong. For queries where any stale answer is unacceptable, Redis's documentation also recommends an application-layer check before calling cache.check().
Microsoft Semantic Kernel
Semantic Kernel implements semantic caching through its filter middleware system. The IPromptRenderFilter interface fires before the LLM is called and is the designed extension point for routing decisions. In Semantic Kernel's caching model, setting context.Result to a non-null value tells the framework to skip the LLM call and return that value directly — so a caching filter stores and retrieves results by managing context.Result. To bypass the cache for volatile queries, the filter simply calls next(context) without touching context.Result, leaving the LLM call to proceed normally:
public class VolatileAwareCacheFilter : IPromptRenderFilter
{
private readonly ISemanticCache _cache;
public async Task OnPromptRenderAsync(
PromptRenderContext context,
Func<PromptRenderContext, Task> next)
{
// Volatile queries skip both cache lookup and storage
if (IsVolatile(context.RenderedPrompt))
{
await next(context); // LLM called directly, no caching
return;
}
// Non-volatile: check cache first
var cached = await _cache.GetAsync(context.RenderedPrompt);
if (cached is not null)
{
context.Result = cached; // setting Result skips the LLM call
return;
}
await next(context); // cache miss — LLM is called
// store result for next time
await _cache.SetAsync(context.RenderedPrompt, context.Result);
}
}The official Semantic Kernel caching sample (SemanticCachingWithFilters.cs) caches all prompts uniformly — no volatile detection included. The filter interface exists precisely so the application team can add that logic. The framework provides the hook; the application provides the classifier.
LlamaIndex
LlamaIndex's IngestionCache is hash-based (keyed on node content), not time-aware. Its LLM response caching historically delegated to LangChain's global cache. There is no native skip-cache API in core LlamaIndex. A GitHub issue requesting per-query cache bypass was closed without resolution, with the application-layer conditional documented as the intended approach.
Walmart's waLLMartCache: A Production-Scale Reference
The most concrete published architecture for this problem at scale comes from Walmart's internal waLLMartCache system, described in a 2024 ICPR paper. For a high-throughput e-commerce search and pricing platform, Walmart built an explicit Decision Engine with a dedicated Temporal Context Detection module. Its job is to intercept every query before any cache operation and classify it as static (cacheable) or dynamic (volatile). Dynamic queries — live inventory lookups, real-time pricing, time-sensitive promotions — are routed directly to the LLM/RAG pipeline, bypassing the cache entirely.
This is not an open-source library. It is a custom production system. But it is the most detailed published example of this architectural pattern operating at e-commerce scale, and it makes the same design choice: volatile detection is a pre-cache routing layer built by the application team, not a feature embedded in the cache infrastructure.
What the Ecosystem Agrees On
Across open-source libraries, managed services, and internal production systems, the pattern is identical:
| Product | Built-in volatile detection | Application-layer mechanism |
|---|---|---|
| GPTCache | No |
|
| LangChain semantic cache | No | Pre-call conditional |
| RedisVL / LangCache | No | Pre-call conditional, per-entry TTL |
| Microsoft Semantic Kernel | No |
|
| LlamaIndex | No | Pre-call conditional |
| pg_semantic_cache | No | Pre-call |
The reason is the same everywhere: the cache operates on vectors, and volatility is a property of the query's relationship to time. No vector encodes the fact that its source question requires a live answer. The application — which knows the domain, knows the user, and controls the query routing logic — is the right layer to make that call. The entire ecosystem is built around this expectation.
Putting It All Together
Volatile query handling is not a caching problem. It is a query routing problem, and query routing is the application's domain. Here is the complete picture:
| Query type | What happens | Owned by |
|---|---|---|
| Volatile — time or live data | Routed directly to LLM, cache not touched | Application |
| Non-volatile, first occurrence | LLM called, result stored via | Application |
| Non-volatile, similar rephrasing | Result returned via | pg_semantic_cache |
pg_semantic_cache handles the third row with precision and efficiency — that is its job, and it does it well. The application handles the first two by classifying queries before they reach the cache. Each layer does what it is designed to do.
Adding a volatile classifier to your application is a small change. One regex match per query. Zero database round-trips on the volatile path. The result is a semantic cache that is always correct for the queries it handles, because the application has already ensured that only the right queries reach it.
Try it yourself. A complete Docker example is available at examples/volatile_query_detection/ in the pg_semantic_cache repository. It runs PostgreSQL 18, pg_semantic_cache built from source, and Ollama locally — no API keys required.
cd examples/volatile_query_detection
docker compose up --build
