Going Rogue: Autonomous AI Agents and Postgres
I recently attended the AI Agent Conference in New York, and almost immediately declared the trip a failure. The conference planners had delegated the engineering track to the chronically over-capacity (yet gigantic) Trianon Ballroom, and I didn't manage to attend any talks there on the first day due to the crowding. Worse yet, talks were 20-minutes long and placed back-to-back, meaning it stayed full all day.
But the second day? I rushed to Trianon an hour early, determined to make the trip worthwhile. Despite the short 20-minute presentations, I saw a lot of valuable content from equally impressive speakers. Two specific talks lingered in my mind beyond the closing ceremonies. The first was a talk by Julie Yanches of NVIDIA addressed workflow automation, and the second by Barr Moses of Monte Carlo covered successful agent stacks.
Both seemingly aimed to answer perhaps the ultimate question regarding autonomous AI agents: how do you keep them from going off the rails? How can we trust their output in production? Is that even a desirable outcome? Based on these talks and a few others in my notes that day, I distilled the problem down to three essential elements:
A global action ledger.
Agent pipelines.
Centralized access controls.
I'm a Postgres guy; what am I even doing talking about AI in the first place? This isn't an article about the pgEdge AI DBA Workbench or Agentic AI Toolkit, and we don't have any autonomous AI agents (yet). So what is this about?
Believe it or not, it's about Postgres.
One is the Loneliest Number
The default mental model for an AI agent is a single entity that receives a task, reasons about it, and produces a result. That's what everyone is used to, and it's a very powerful approach on its own. The problem is that a lone agent operating without oversight is remarkably prone to compounding its own mistakes. Anyone with experience in the area has seen a task go awry, sometimes catastrophically.
An agent can hallucinate a fact, build on that hallucination in the next step, and confidently deliver a finished product that's wrong in ways nobody catches until it's too late. There's no second pair of eyes. There's no editorial review. There's no one asking "wait, where did you get that number?"
Every real production system ever built has some fundamental quality guidelines. We don't let a single developer push straight to production or let a single accountant sign off on their own audits. PRs require CI, tests, and review before merge and deployment. Why would we let a single AI agent run unmonitored?
Obviously we wouldn't. But what if, at least to some small extent, we could?
Making Henry Ford Proud
Almost nothing gets built in isolation. Pipelines are everywhere if you stop to think about it, so it's inevitable to apply the same concept to agents. Rather than one agent wrestling with an entire complex task, break the work into discrete steps. Then assign a purpose-built agent to each segment of the assembly line. It's a lot harder for an agent to ignore one or two rules or a highly refined single-purpose prompt than a project's worth of instructions and an equally polluted context window that may require several rounds of lossy compaction.
Consider the case of a newsroom. One agent researches, another drafts, another edits, another checks references, another handles graphics, and so on. Each step has clear input requirements and output standards. And critically, any step can kick work back to a previous step for revisions. The editor sends a sloppy draft back to the writer. The fact-checker flags an unsupported claim and bounces it to research. The pipeline keeps cycling until every stage is satisfied.
The reason Patroni is so successful as a Postgres HA tool is because the consensus layer is integral to the design. The node fencing is inescapable. It's impossible to have an active Split Brain. No other previous HA system did that. The workflow must reflect the intended outcome.
With agents, the trick is integrating the guidelines into the process. No single agent can circumvent an instruction by claiming ignorance or arbitrarily proceeding. Each step produces some artifact which is then checked by at least one subsequent step in the pipeline. Each agent in the pipeline acts as a checkpoint for the ones that came before it. Quality control, compliance requirements, style guidelines, and domain-specific standards are all enforced at the appropriate step.
Here’s how that might look:
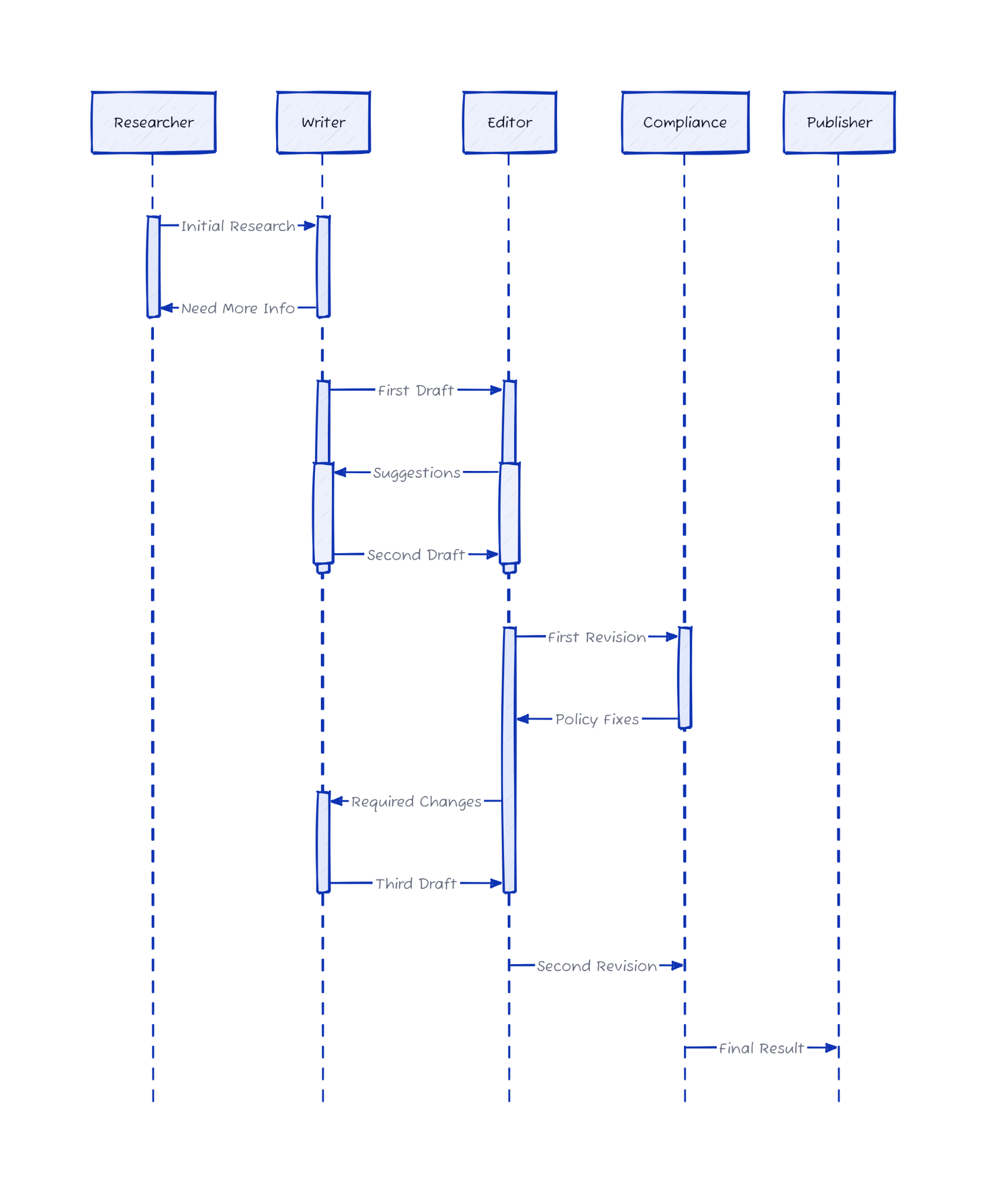
The beauty of this approach is its malleability. A content pipeline looks different from a data pipeline, which looks different from a customer service pipeline. But the pattern is identical: decompose, specialize, enforce, iterate. And every one of those operations needs to be recorded somewhere.
Iron Mountain
Just as every bank has a ledger, so too must all actions taken by every agent in every pipeline be logged. Not “logged” in the sense of dumping text to a file that nobody reads until something catches fire. Logged in the sense of an authoritative and auditable record that other systems can act on in real time.
Why not just use a log aggregation service? Because logs are for humans to read after the fact. A ledger is for other agents to query while work is still in progress. A monitoring agent needs to ask questions like:
How long has pipeline #4721 been stuck on the compliance step?
Which agent has been making the most API calls in the last hour?
Show me every action taken on this document since it entered the pipeline.
Which workloads have iterated up to three steps more than five times consecutively?
Those are obvious SQL queries.
The ledger also has to be trustworthy. If a monitoring agent decides to halt a pipeline based on what it reads in the ledger, that data must be consistent and durable. Sounds like a database, doesn't it? Now we're getting closer.
Guardrails and Gatekeepers
The ledger alone isn't quite enough. It's also necessary to have a central authority for what agents are allowed to do.
At the conference, this came up as a kind of ACL system, though the concept goes beyond traditional access control. It's a combination of permissions, guidelines, and policies. It allows us to control which APIs or tools agents can call, the behavioral definition of each agent, and success or failure criteria. All of that belongs in a queryable, versioned, centralized repository.
Why centralized? Because scattering agent guidelines across config files, environment variables, and hardcoded prompts is a recipe for drift. When a monitoring agent detects an anomaly, it needs to check the current guidelines for that pipeline step. If it determines the guidelines need updating, those modifications should propagate immediately to every agent that reads them. What easier way to do that than a database transaction?
The monitoring agents themselves are the most fascinating piece of this architecture. They watch the ledger for abnormalities: a pipeline that's been looping too long, an agent that's burning through API quota, a step that keeps producing output the next step rejects. When they spot something wrong, they can halt the pipeline, launch an investigation agent to diagnose the root cause, and even update the guidelines or revoke permissions to prevent recurrence.
It's agents all the way down.
Enter Postgres
So we need a system that provides ACID-compliant transactional storage, flexible semi-structured data, queries, row-level access control, and ideally semantic search capabilities for natural-language log analysis.
Hmm... sounds familiar.
The action ledger is a table (or a set of partitioned tables, if we're being responsible about scale). Pipeline definitions, agent guidelines, and policies are relational data with JSONB columns for the parts that vary per agent type. Row-level security can enforce that each agent only sees the guidelines and permissions relevant to its role. And with pgvector, monitoring agents can perform semantic searches over the ledger.
Let's say a monitoring agent needs to find actions similar to a known failure pattern, not just actions that match a specific error code:
SELECT agent_id, action_type, step_name, details
FROM agent_ledger
WHERE event_time >= $1
ORDER BY log_embedding <=> $2
LIMIT 20;A monitoring agent could vectorize its description of the anomaly and find related incidents across the entire ledger, even if they used completely different terminology or occurred in unrelated pipelines. Most monitor agents would perform more focused checks on specific pipelines in most cases, but global sanity checks like this are also possible.
Postgres isn't being shoe-horned into this role. This is what it already does: store structured data reliably, enforce access control, support flexible queries, and serve as the single source of truth everything else depends on.
Going global with Spock
There's a catch, though. AI agents don't always operate in a single data center. Pipelines may run across regions. A content moderation pipeline might have agents in the US, EU, and APAC, each working on region-specific content but all writing to the same global ledger. A single-region Postgres instance becomes a bottleneck and a single point of failure for the entire agent fleet.
This is where pgEdge Enterprise Postgres enters the picture. Our open-source Spock extension provides multi-master logical replication for Postgres, meaning every node can accept writes simultaneously. An agent in Frankfurt writes to the local Postgres node, an agent in Virginia writes to its local node, and Spock replicates the changes bidirectionally with conflict resolution built in.
For an action ledger specifically, this is close to ideal. Ledger entries are almost exclusively inserts (agent actions are immutable facts), which means write conflicts are essentially nonexistent. The timestamp-based conflict resolution and delta-apply algorithm handle the edge cases where they do arise, and every conflict resolution event gets captured in its own Postgres table for audit.
Here’s what the entire picture might resemble after including pgEdge Distributed Postgres:
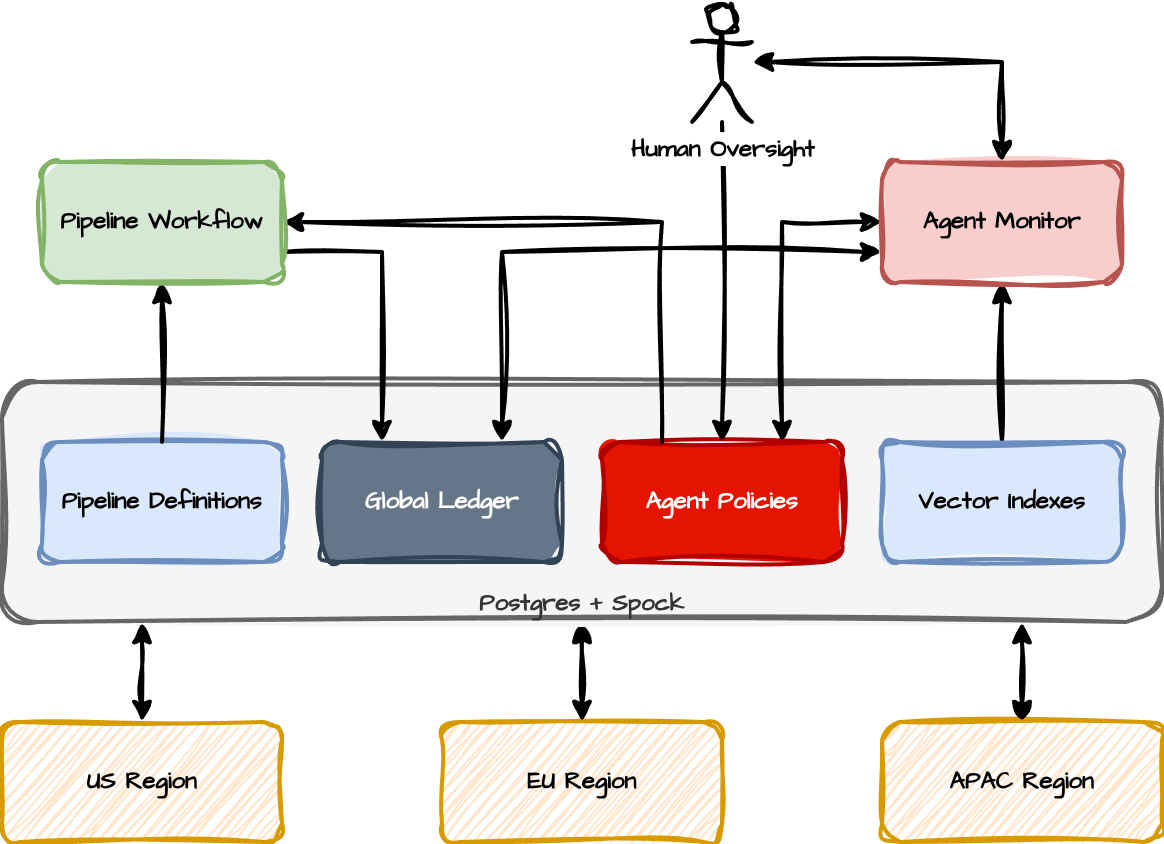
The pipelines read from the definitions and policies to control agent behavior and the distinct series of steps expected, all while logging all actions in the ledger. The monitors observe the ledger using various techniques and then modify the agent policies to influence the Pipeline. And all of that is distributed across multiple regions thanks to the pgEdge Spock extension.
Who Watches the Watchmen?
Who else? We do. The diagram didn’t include a “Human Oversight” figure for nothing!
It's not really possible to remove humans from the loop (yet). In reality, this approach makes the human's job possible. Without structured pipelines, a centralized ledger, and monitoring agents, a regular person facing a fleet of autonomous AI agents is likely to be overwhelmed. They have no way to understand what's happening, let alone intervene when something goes sideways. There could be tens of thousands of these things operating simultaneously, and no dashboard can really summarize that effectively.
Without this infrastructure in place, a person would have to manually review all output. Devs are already being absolutely inundated with PRs from countless agents, so we already know that doesn't scale. But a pipeline allows us to set the guidelines, review the exceptions, and investigate the anomalies flagged by monitors instead. The monitoring agents surface the small percentage of activity that resists automated correction and needs human attention. There could also be a dashboard summary with drill-down for in-depth investigation.
And Postgres is the institutional memory at the center of it all. Every action recorded, every guideline versioned, every permission enforced, every anomaly searchable. The agents may be new, but Postgres isn't. It's the battle-tested relational database we've all known and loved for decades.
Everyone talks about RAG and pgvector when it comes to Postgres and AI, but there's far more potential being overlooked. Postgres is a database after all, so why not leverage its most fundamental capabilities for day-to-day operation of the stack itself, rather than focus on semantic search and vectors? Implement the ledger there, define and coordinate the agent pipelines there, and never look back.
Postgres eats this kind of workload for breakfast.

